

In this blog post, I show how to build a read-only view-API for Oracle’s HR sample schema. And I will use this view-API in a JOOQ application. This application will fully comply with the Pink Database Paradigm (PinkDB). This means the application executes set-based SQL and retrieves data with as few network roundtrips as possible.
The following topics are covered:
- Install Sample Schemas
- Build the View-API
- Create the View-API Database Role
- Create the Connect User
- Install JOOQ
- Teach JOOQ the View-API
- Run a Simple Query
- Using Joins & Aggregations
- Using Bind Variables
- Run a Top N Query
- Using Row Pattern Matching
- Conclusion
This is not meant to be a tutorial. However, you should be able to build the application based on the information in this blog post and the referenced links.
It’s the first time I’ve done anything with JOOQ. I read about it and understood the high-level concepts, but I have never used JOOQ before. This is one reason why this blog post became a bit more verbose. I hope it is helpful.
1. Install Sample Schemas
See the Oracle documentation.
Starting with Oracle Database 12c Release 2, the latest version of the sample schema scripts are available on GitHub at https://github.com/oracle/db-sample-schemas/releases/latest. (…)
2. Build the View-API
1:1 Views
When building a view API I start with a 1:1 mapping to the table. There are usually some discussions on different topics.
Expose Surrogate Keys
One topic is to include surrogate keys or just business keys in the view API. Nowadays, I tend to expose surrogate keys. The main reason is to avoid joins when business key columns are stored in related (parent) tables. Forcing the application to join views via such business key columns is a bad idea from a performance point of view.
Convenience Views – Not a Replacement for 1:1 Views
Another topic is the simplification of the model. For example, provide data from various tables to simplify the usage. Simplification means here sparing the consuming application to use joins. This is sometimes a good idea, but it does not replace the 1:1 views, which are the key to the optimal path to the data. I know about join elimination, but in reality, they often do not work. One reason is that unnecessary columns are queried as well. Another problem is, to force the view to apply selective predicates as early as possible. Sometimes it is necessary to introduce an application context, just for that purpose, making the usage of the view not that simple anymore.
Value of a 1:1 View-API
The logical next question is this: Why do we need a view layer when it just provides data the same way as the underlying tables? That’s an excellent question. I strongly recommend introducing a layer only, when it provides more value than the additional effort. So, what is the value of a 1:1 view layer? Most products evolve during their life cycle. Hence, the data model will most probably change as well. When we have a view layer, we have the option to change the physical data model and keep the existing view layer the same for the consuming applications. From that point on, the views are not a 1:1 representation of tables, at least not in every case.
As long as we keep the interface to the application unchanged, we do not have to coordinate changes with the consuming applications. This gives us effective room for refactoring and simplifies going-live scenarios of new releases. Providing additional data and functionality is usually not a problem. However, adapting applications to new interfaces needs time. A view-API, especially if it implements some versioning concept, provides an excellent value in this area.
View-API of HR Schema
I’ve generated the initial version of the 1:1 view layer with oddgen‘s 1:1 View generator.
ALTER SESSION SET current_schema=hr;
CREATE OR REPLACE VIEW COUNTRIES_V AS
SELECT COUNTRY_ID,
COUNTRY_NAME,
REGION_ID
FROM COUNTRIES;
CREATE OR REPLACE VIEW DEPARTMENTS_V AS
SELECT DEPARTMENT_ID,
DEPARTMENT_NAME,
MANAGER_ID,
LOCATION_ID
FROM DEPARTMENTS;
CREATE OR REPLACE VIEW EMPLOYEES_V AS
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
PHONE_NUMBER,
HIRE_DATE,
JOB_ID,
SALARY,
COMMISSION_PCT,
MANAGER_ID,
DEPARTMENT_ID
FROM EMPLOYEES;
CREATE OR REPLACE VIEW JOB_HISTORY_V AS
SELECT EMPLOYEE_ID,
START_DATE,
END_DATE,
JOB_ID,
DEPARTMENT_ID
FROM JOB_HISTORY;
CREATE OR REPLACE VIEW JOBS_V AS
SELECT JOB_ID,
JOB_TITLE,
MIN_SALARY,
MAX_SALARY
FROM JOBS;
CREATE OR REPLACE VIEW LOCATIONS_V AS
SELECT LOCATION_ID,
STREET_ADDRESS,
POSTAL_CODE,
CITY,
STATE_PROVINCE,
COUNTRY_ID
FROM LOCATIONS;
CREATE OR REPLACE VIEW REGIONS_V AS
SELECT REGION_ID,
REGION_NAME
FROM REGIONS;View Constraints
When building a view-API it is a good idea to also define primary key, foreign key and unique constraints for these views. They will not be enforced by the Oracle database, but they are an excellent documentation. Furthermore, they will be used by JOOQ as we see later.
ALTER SESSION SET current_schema=hr;
-- primary key and unique constraints
ALTER VIEW countries_v ADD PRIMARY KEY (country_id) DISABLE NOVALIDATE;
ALTER VIEW departments_v ADD PRIMARY KEY (department_id) DISABLE NOVALIDATE;
ALTER VIEW employees_v ADD PRIMARY KEY (employee_id) DISABLE NOVALIDATE;
ALTER VIEW employees_v ADD UNIQUE (email) DISABLE NOVALIDATE;
ALTER VIEW job_history_v ADD PRIMARY KEY (employee_id, start_date) DISABLE NOVALIDATE;
ALTER VIEW jobs_v ADD PRIMARY KEY (job_id) DISABLE NOVALIDATE;
ALTER VIEW locations_v ADD PRIMARY KEY (location_id) DISABLE NOVALIDATE;
ALTER VIEW regions_v ADD PRIMARY KEY (region_id) DISABLE NOVALIDATE;
-- foreign key constraints
ALTER VIEW countries_v ADD FOREIGN KEY (region_id) REFERENCES hr.regions_v DISABLE NOVALIDATE;
ALTER VIEW departments_v ADD FOREIGN KEY (location_id) REFERENCES hr.locations_v DISABLE NOVALIDATE;
ALTER VIEW departments_v ADD FOREIGN KEY (manager_id) REFERENCES hr.employees_v DISABLE NOVALIDATE;
ALTER VIEW employees_v ADD FOREIGN KEY (department_id) REFERENCES hr.departments_v DISABLE NOVALIDATE;
ALTER VIEW employees_v ADD FOREIGN KEY (job_id) REFERENCES hr.jobs_v DISABLE NOVALIDATE;
ALTER VIEW employees_v ADD FOREIGN KEY (manager_id) REFERENCES hr.employees_v DISABLE NOVALIDATE;
ALTER VIEW job_history_v ADD FOREIGN KEY (department_id) REFERENCES hr.departments_v DISABLE NOVALIDATE;
ALTER VIEW job_history_v ADD FOREIGN KEY (employee_id) REFERENCES hr.employees_v DISABLE NOVALIDATE;
ALTER VIEW job_history_v ADD FOREIGN KEY (job_id) REFERENCES hr.jobs_v DISABLE NOVALIDATE;
ALTER VIEW locations_v ADD FOREIGN KEY (country_id) REFERENCES hr.countries_v DISABLE NOVALIDATE;View-API Model
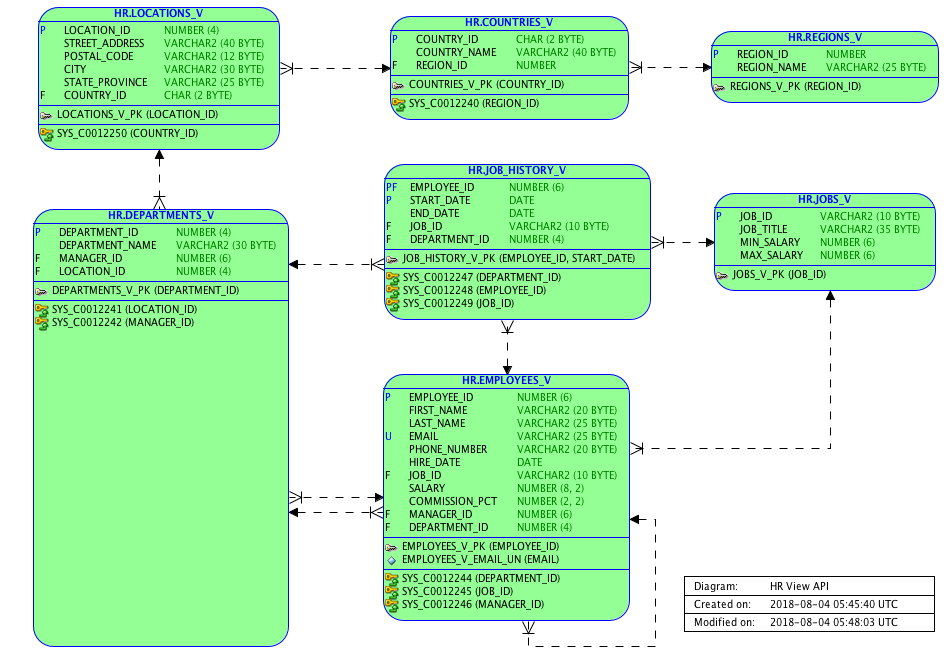
I created the following relational model with Oracle’s SQL Developer. SQL Developer automatically took into account all constraints defined on these 7 views. Most of the work was to rearrange the view boxes on the diagram, but with only 7 views it was no big deal.
3. Create the View-API Database Role
We grant read access to all views as part of the API to the database role HR_API_ROLE. This is easier to maintain, especially when access to more than one connect user is granted.
Please note that just READ access is granted on the views. We do not grant SELECT access to ensure that data can’t be locked by the connect users via SELECT FOR UPDATE. The READ privilege was introduced in Oracle Database 12c.
CREATE ROLE hr_api_role;
GRANT READ ON hr.countries_v TO hr_api_role;
GRANT READ ON hr.departments_v TO hr_api_role;
GRANT READ ON hr.employees_v TO hr_api_role;
GRANT READ ON hr.job_history_v TO hr_api_role;
GRANT READ ON hr.jobs_v TO hr_api_role;
GRANT READ ON hr.locations_v TO hr_api_role;
GRANT READ ON hr.regions_v TO hr_api_role;In this case, it does not make sense to define more than one role. But for larger projects, it might be helpful to create more roles. For example to distinguish between read and write roles or to manage access to sensitive data explicitly.
4. Create the Connect User
Now we create a connect user named JOOQ. It will have the right to connect, access the view-API and execute the procedures in the SYS.DBMS_MONITOR package. The access to DBMS_MONITOR is given only to enable SQL Trace for some analysis on the database server.
CREATE USER jooq IDENTIFIED BY jooq;
GRANT connect, hr_api_role TO jooq;
GRANT EXECUTE ON sys.dbms_monitor TO jooq;5. Install JOOQ
Download the trial version of JOOQ Professional for free. The trial period is 30 days. Registration is not required.
JOOQ comes with an excellent documentation. In fact, I kept the PDF version open during all my tests and found everything I needed using the search function. After extracting the downloaded ZIP file, I run the following commands on my macOS system:
chmod +x maven-deploy.sh
./maven-deploy.sh -u file:///Users/phs/.m2/repositoryThis deployed JOOQ in my local Maven repository. Run ./maven-deploy.sh -h for command line options, e.g. when you want to deploy it on your Sonatype Nexus repository.
6. Teach JOOQ the View-API
JOOQ allows to build SQL and execute SQL statements in a typesafe manner. It’s similar to SQL within PL/SQL. You avoid to build SQL using string concatenation. Instead, you use the JOOQ domain-specific language (DSL) that knows about SQL and can learn about your database model. For example, JOOQ must learn that JOBS_V is a view and JOB_ID is its primary key column.
Technically JOOQ reads the data dictionary and generates a set of Java classes for you. You may call the generator via command line using a XML configuration file or use the JOOQ Maven plugin to configure the generator directly in your pom.xml. You may also generate these classes via Ant or Gradle. I’ve used the Maven plugin to include the code generation process in my project build.
On lines 36-38, we define the JDBC driver.
On lines 43-46, we configure the JDBC URL and the credentials of the connect user.
Line 50 tells JOOQ to use the Oracle meta-model and line 51 is a regular expression to define the generation scope. In our case the visible objects in the HR schema and the PL/SQL package SYS.DBMS_MONITOR. Using the default would generate Java code for all public objects.
Finally, on lines 54-55, we define the target directory for the generated Java classes and their Java package name.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.pinkdb.jooq</groupId>
<artifactId>jooq-pinkdb</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jdk.version>1.8</jdk.version>
<xtend.version>2.12.0</xtend.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<version>3.8.0</version>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${jdk.version}</source>
<target>${jdk.version}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.jooq.trial</groupId>
<artifactId>jooq-codegen-maven</artifactId>
<version>3.11.3</version>
<executions>
<execution>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>oracle</groupId>
<artifactId>ojdbc8</artifactId>
<version>12.2.0.1.0</version>
</dependency>
</dependencies>
<configuration>
<jdbc>
<driver>oracle.jdbc.OracleDriver</driver>
<url>jdbc:oracle:thin:@localhost:1521/odb.docker</url>
<user>jooq</user>
<password>jooq</password>
</jdbc>
<generator>
<database>
<name>org.jooq.meta.oracle.OracleDatabase</name>
<includes>HR\..*|SYS\.DBMS_MONITOR</includes>
</database>
<target>
<packageName>com.trivadis.jooq.pinkdb.model.generated</packageName>
<directory>src/main/java</directory>
</target>
</generator>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.jooq.trial</groupId>
<artifactId>jooq</artifactId>
<version>3.11.3</version>
</dependency>
<dependency>
<groupId>oracle</groupId>
<artifactId>ojdbc8</artifactId>
<version>12.2.0.1.0</version>
</dependency>
</dependencies>
</project>Here’s the excerpt of the console output (of mvn package) regarding the generation run:
[INFO] --- jooq-codegen-maven:3.11.3:generate (default) @ jooq-pinkdb ---
[INFO] No <inputCatalog/> was provided. Generating ALL available catalogs instead.
[INFO] No <inputSchema/> was provided. Generating ALL available schemata instead.
[INFO] License parameters
[INFO] ----------------------------------------------------------
[INFO] Thank you for using jOOQ and jOOQ's code generator
[INFO]
[INFO] Database parameters
[INFO] ----------------------------------------------------------
[INFO] dialect : ORACLE
[INFO] URL : jdbc:oracle:thin:@localhost:1521/odb.docker
[INFO] target dir : /Users/phs/git/JooqPinkDB/src/main/java
[INFO] target package : com.trivadis.jooq.pinkdb.model.generated
[INFO] includes : [HR\..*|SYS\.DBMS_MONITOR]
[INFO] excludes : []
[INFO] includeExcludeColumns : false
[INFO] ----------------------------------------------------------
[INFO]
[INFO] JavaGenerator parameters
[INFO] ----------------------------------------------------------
[INFO] annotations (generated): true
[INFO] annotations (JPA: any) : false
[INFO] annotations (JPA: version):
[INFO] annotations (validation): false
[INFO] comments : true
[INFO] comments on attributes : true
[INFO] comments on catalogs : true
[INFO] comments on columns : true
[INFO] comments on keys : true
[INFO] comments on links : true
[INFO] comments on packages : true
[INFO] comments on parameters : true
[INFO] comments on queues : true
[INFO] comments on routines : true
[INFO] comments on schemas : true
[INFO] comments on sequences : true
[INFO] comments on tables : true
[INFO] comments on udts : true
[INFO] daos : false
[INFO] deprecated code : true
[INFO] global references (any): true
[INFO] global references (catalogs): true
[INFO] global references (keys): true
[INFO] global references (links): true
[INFO] global references (queues): true
[INFO] global references (routines): true
[INFO] global references (schemas): true
[INFO] global references (sequences): true
[INFO] global references (tables): true
[INFO] global references (udts): true
[INFO] indexes : true
[INFO] instance fields : true
[INFO] interfaces : false
[INFO] interfaces (immutable) : false
[INFO] javadoc : true
[INFO] keys : true
[INFO] links : true
[INFO] pojos : false
[INFO] pojos (immutable) : false
[INFO] queues : true
[INFO] records : true
[INFO] routines : true
[INFO] sequences : true
[INFO] table-valued functions : false
[INFO] tables : true
[INFO] udts : true
[INFO] relations : true
[INFO] ----------------------------------------------------------
[INFO]
[INFO] Generation remarks
[INFO] ----------------------------------------------------------
[INFO]
[INFO] ----------------------------------------------------------
[INFO] Generating catalogs : Total: 1
[INFO]
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@ @@ @@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@
@@@@@@@@@@@@@@@@ @@ @@ @@@@@@@@@@
@@@@@@@@@@ @@@@ @@ @@ @@@@@@@@@@
@@@@@@@@@@ @@ @@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@ @@ @@@@@@@@@@
@@@@@@@@@@ @@ @@ @@@@ @@@@@@@@@@
@@@@@@@@@@ @@ @@ @@@@ @@@@@@@@@@
@@@@@@@@@@ @@ @ @ @@@@@@@@@@
@@@@@@@@@@ @@ @@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Thank you for using the 30 day free jOOQ 3.11.3 trial edition
[INFO] Packages fetched : 517 (1 included, 516 excluded)
[INFO] Applying synonym : "PUBLIC"."KU$_LOGENTRY" is synonym for "SYS"."KU$_LOGENTRY1010"
[INFO] Applying synonym : "PUBLIC"."XMLTYPE" is synonym for "SYS"."XMLTYPE"
[INFO] ARRAYs fetched : 641 (0 included, 641 excluded)
[INFO] Enums fetched : 0 (0 included, 0 excluded)
[INFO] No schema version is applied for catalog . Regenerating.
[INFO]
[INFO] Generating catalog : DefaultCatalog.java
[INFO] ==========================================================
[INFO] Routines fetched : 312 (0 included, 312 excluded)
[INFO] Tables fetched : 2347 (7 included, 2340 excluded)
[INFO] UDTs fetched : 1287 (0 included, 1287 excluded)
[INFO] Generating schemata : Total: 63
[INFO] No schema version is applied for schema SYS. Regenerating.
[INFO] Generating schema : Sys.java
[INFO] ----------------------------------------------------------
[INFO] Sequences fetched : 12 (0 included, 12 excluded)
[INFO] Domains fetched : 0 (0 included, 0 excluded)
[INFO] Generating packages
[INFO] Generating package : SYS.DBMS_MONITOR
[INFO] Generating routine : ClientIdStatDisable.java
[INFO] Generating routine : ClientIdStatEnable.java
[INFO] Generating routine : ClientIdTraceDisable.java
[INFO] Generating routine : ClientIdTraceEnable.java
[INFO] Generating routine : DatabaseTraceDisable.java
[INFO] Generating routine : DatabaseTraceEnable.java
[INFO] Generating routine : ServModActStatDisable.java
[INFO] Generating routine : ServModActStatEnable.java
[INFO] Generating routine : ServModActTraceDisable.java
[INFO] Generating routine : ServModActTraceEnable.java
[INFO] Generating routine : SessionTraceDisable.java
[INFO] Generating routine : SessionTraceEnable.java
[INFO] Packages generated : Total: 7.009s
[INFO] UDT not supported or not in input schemata: SYS.SCHEDULER$_EVENT_INFO
[INFO] UDT not supported or not in input schemata: SYS.SCHEDULER_FILEWATCHER_RESULT
[INFO] Queues fetched : 0 (0 included, 0 excluded)
[INFO] Links fetched : 0 (0 included, 0 excluded)
[INFO] Generation finished: SYS : Total: 7.482s, +473.374ms
[INFO]
[INFO] Excluding empty schema : AUDSYS
[INFO] Excluding empty schema : SYSTEM
[INFO] Excluding empty schema : SYSBACKUP
[INFO] Excluding empty schema : SYSDG
[INFO] Excluding empty schema : SYSKM
[INFO] Excluding empty schema : SYSRAC
[INFO] Excluding empty schema : OUTLN
[INFO] Excluding empty schema : XS$NULL
[INFO] Excluding empty schema : GSMADMIN_INTERNAL
[INFO] Excluding empty schema : GSMUSER
[INFO] Excluding empty schema : DIP
[INFO] Excluding empty schema : REMOTE_SCHEDULER_AGENT
[INFO] Excluding empty schema : DBSFWUSER
[INFO] Excluding empty schema : ORACLE_OCM
[INFO] Excluding empty schema : SYS$UMF
[INFO] Excluding empty schema : DBSNMP
[INFO] Excluding empty schema : APPQOSSYS
[INFO] Excluding empty schema : GSMCATUSER
[INFO] Excluding empty schema : GGSYS
[INFO] Excluding empty schema : XDB
[INFO] Excluding empty schema : ANONYMOUS
[INFO] Excluding empty schema : WMSYS
[INFO] Excluding empty schema : DVF
[INFO] Excluding empty schema : OJVMSYS
[INFO] Excluding empty schema : CTXSYS
[INFO] Excluding empty schema : ORDSYS
[INFO] Excluding empty schema : ORDDATA
[INFO] Excluding empty schema : ORDPLUGINS
[INFO] Excluding empty schema : SI_INFORMTN_SCHEMA
[INFO] Excluding empty schema : MDSYS
[INFO] Excluding empty schema : OLAPSYS
[INFO] Excluding empty schema : MDDATA
[INFO] Excluding empty schema : LBACSYS
[INFO] Excluding empty schema : DVSYS
[INFO] Excluding empty schema : FLOWS_FILES
[INFO] Excluding empty schema : APEX_PUBLIC_USER
[INFO] Excluding empty schema : APEX_180100
[INFO] Excluding empty schema : APEX_INSTANCE_ADMIN_USER
[INFO] Excluding empty schema : APEX_LISTENER
[INFO] Excluding empty schema : APEX_REST_PUBLIC_USER
[INFO] Excluding empty schema : ORDS_METADATA
[INFO] Excluding empty schema : ORDS_PUBLIC_USER
[INFO] Excluding empty schema : SCOTT
[INFO] No schema version is applied for schema HR. Regenerating.
[INFO] Generating schema : Hr.java
[INFO] ----------------------------------------------------------
[INFO] Generating tables
[INFO] Adding foreign key : SYS_C0012240 (HR.COUNTRIES_V.REGION_ID) referencing SYS_C0012239
[INFO] Adding foreign key : SYS_C0012241 (HR.DEPARTMENTS_V.LOCATION_ID) referencing SYS_C0012238
[INFO] Adding foreign key : SYS_C0012242 (HR.DEPARTMENTS_V.MANAGER_ID) referencing SYS_C0012235
[INFO] Adding foreign key : SYS_C0012244 (HR.EMPLOYEES_V.DEPARTMENT_ID) referencing SYS_C0012234
[INFO] Adding foreign key : SYS_C0012245 (HR.EMPLOYEES_V.JOB_ID) referencing SYS_C0012237
[INFO] Adding foreign key : SYS_C0012246 (HR.EMPLOYEES_V.MANAGER_ID) referencing SYS_C0012235
[INFO] Adding foreign key : SYS_C0012247 (HR.JOB_HISTORY_V.DEPARTMENT_ID) referencing SYS_C0012234
[INFO] Adding foreign key : SYS_C0012248 (HR.JOB_HISTORY_V.EMPLOYEE_ID) referencing SYS_C0012235
[INFO] Adding foreign key : SYS_C0012249 (HR.JOB_HISTORY_V.JOB_ID) referencing SYS_C0012237
[INFO] Adding foreign key : SYS_C0012250 (HR.LOCATIONS_V.COUNTRY_ID) referencing SYS_C0012233
[INFO] Synthetic primary keys : 0 (0 included, 0 excluded)
[INFO] Overriding primary keys : 8 (0 included, 8 excluded)
[INFO] Generating table : CountriesV.java [input=COUNTRIES_V, output=COUNTRIES_V, pk=SYS_C0012233]
[INFO] Indexes fetched : 0 (0 included, 0 excluded)
[INFO] Generating table : DepartmentsV.java [input=DEPARTMENTS_V, output=DEPARTMENTS_V, pk=SYS_C0012234]
[INFO] Generating table : EmployeesV.java [input=EMPLOYEES_V, output=EMPLOYEES_V, pk=SYS_C0012235]
[INFO] Generating table : JobsV.java [input=JOBS_V, output=JOBS_V, pk=SYS_C0012237]
[INFO] Generating table : JobHistoryV.java [input=JOB_HISTORY_V, output=JOB_HISTORY_V, pk=SYS_C0012236]
[INFO] Generating table : LocationsV.java [input=LOCATIONS_V, output=LOCATIONS_V, pk=SYS_C0012238]
[INFO] Generating table : RegionsV.java [input=REGIONS_V, output=REGIONS_V, pk=SYS_C0012239]
[INFO] Tables generated : Total: 13.888s, +6.405s
[INFO] Generating table references
[INFO] Table refs generated : Total: 13.889s, +1.9ms
[INFO] Generating Keys
[INFO] Keys generated : Total: 13.9s, +10.228ms
[INFO] Generating Indexes
[INFO] Skipping empty indexes
[INFO] Generating table records
[INFO] Generating record : CountriesVRecord.java
[INFO] Generating record : DepartmentsVRecord.java
[INFO] Generating record : EmployeesVRecord.java
[INFO] Generating record : JobsVRecord.java
[INFO] Generating record : JobHistoryVRecord.java
[INFO] Generating record : LocationsVRecord.java
[INFO] Generating record : RegionsVRecord.java
[INFO] Table records generated : Total: 13.939s, +39.368ms
[INFO] Generation finished: HR : Total: 13.939s, +0.14ms
[INFO]
[INFO] Excluding empty schema : OE
[INFO] Excluding empty schema : PM
[INFO] Excluding empty schema : IX
[INFO] Excluding empty schema : SH
[INFO] Excluding empty schema : BI
[INFO] Excluding empty schema : FTLDB
[INFO] Excluding empty schema : TEPLSQL
[INFO] Excluding empty schema : ODDGEN
[INFO] Excluding empty schema : OGDEMO
[INFO] Excluding empty schema : AQDEMO
[INFO] Excluding empty schema : AX
[INFO] Excluding empty schema : EMPTRACKER
[INFO] Excluding empty schema : UT3
[INFO] Excluding empty schema : PLSCOPE
[INFO] Excluding empty schema : SONAR
[INFO] Excluding empty schema : TVDCA
[INFO] Excluding empty schema : DEMO
[INFO] Excluding empty schema : JOOQ
[INFO] Removing excess files7. Run a Simple Query
The following code is a complete Java program. It contains a bit more than the simple query because I will need these parts in the next chapters and would like to focus on the JOOQ query only.
Java Program (JOOQ Query)
On line 3 the view-API is imported statically. This allows to reference the view JOBS_V instead of JobsV.JOBS_V or Hr.JOBS_V. It’s just convenience, but it makes the code much more readable.
The next static import on line 4 allows for example to use SQL functions such as count(), sum(), etc. without the DSL. prefix. Again, it’s just convenience, but makes to code shorter and improves readability.
On lines 27-28, the DSL context is initialized. The context holds the connection to the database and some configuration. In this case I’ve configured JOOQ to produce formatted SQL statements and fetch data with an array size of 30 from the database. The JDBC default is 10, which is not bad, but 30 is in our case better, since it reduces the network roundtrips to 1 for all SQL query results.
On lines 64-67, we build the SQL statement using the JOOQ DSL. The statement is equivalent to SELECT * FROM hr.jobs_v ORDER BY job_id.
Finally, on line 68 the function fetchAndPrint is called. This function prints the query produced by JOOQ, all used bind variables and the query result. See lines 51, 59 and 60.
package com.trivadis.jooq.pinkdb;
import static com.trivadis.jooq.pinkdb.model.generated.hr.Tables.*;
import static org.jooq.impl.DSL.*;
import com.trivadis.jooq.pinkdb.model.generated.sys.packages.DbmsMonitor;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.List;
import org.jooq.DSLContext;
import org.jooq.Result;
import org.jooq.ResultQuery;
import org.jooq.SQLDialect;
import org.jooq.conf.Settings;
import org.jooq.impl.DSL;
public class Main {
private static DSLContext ctx;
private static boolean sqlTrace = false;
private static void initCtx(boolean withSqlTrace) throws SQLException {
final Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@localhost:1521/odb.docker", "jooq", "jooq");
ctx = DSL.using(conn, SQLDialect.ORACLE12C,
new Settings().withRenderFormatted(true).withFetchSize(30));
sqlTrace = withSqlTrace;
enableSqlTrace();
}
private static void closeCtx() throws SQLException {
disableSqlTrace();
ctx.close();
}
private static void enableSqlTrace() throws SQLException {
if (sqlTrace) {
DbmsMonitor.sessionTraceEnable(ctx.configuration(), null, null, true, true, "all_executions");
}
}
private static void disableSqlTrace() throws SQLException {
if (sqlTrace) {
DbmsMonitor.sessionTraceDisable(ctx.configuration(), null, null);
}
}
private static void fetchAndPrint(String name, ResultQuery<?> query) {
System.out.println(name + ": \n\n" + query.getSQL());
final List<Object> binds = query.getBindValues();
if (binds.size() > 0) {
System.out.println("\n" + name + " binds:");
for (int i=0; i<binds.size(); i++) {
System.out.println(" " + ":" + (i+1) + " = " + binds.get(i));
}
}
final Result<?> result = query.fetch();
System.out.println("\n" + name + " result (" + result.size() + " rows): \n\n" + result.format());
}
private static void queryJobs() {
final ResultQuery<?> query = ctx
.select()
.from(JOBS_V)
.orderBy(JOBS_V.JOB_ID);
fetchAndPrint("Jobs", query);
}
public static void main(String[] args) throws SQLException {
initCtx(true);
queryJobs();
closeCtx();
}
}Java Program Output (SQL Query & Result)
The program produces this output:
Jobs:
select
"HR"."JOBS_V"."JOB_ID",
"HR"."JOBS_V"."JOB_TITLE",
"HR"."JOBS_V"."MIN_SALARY",
"HR"."JOBS_V"."MAX_SALARY"
from "HR"."JOBS_V"
order by "HR"."JOBS_V"."JOB_ID"
Jobs result (19 rows):
+----------+-------------------------------+----------+----------+
|JOB_ID |JOB_TITLE |MIN_SALARY|MAX_SALARY|
+----------+-------------------------------+----------+----------+
|AC_ACCOUNT|Public Accountant | 4200| 9000|
|AC_MGR |Accounting Manager | 8200| 16000|
|AD_ASST |Administration Assistant | 3000| 6000|
|AD_PRES |President | 20080| 40000|
|AD_VP |Administration Vice President | 15000| 30000|
|FI_ACCOUNT|Accountant | 4200| 9000|
|FI_MGR |Finance Manager | 8200| 16000|
|HR_REP |Human Resources Representative | 4000| 9000|
|IT_PROG |Programmer | 4000| 10000|
|MK_MAN |Marketing Manager | 9000| 15000|
|MK_REP |Marketing Representative | 4000| 9000|
|PR_REP |Public Relations Representative| 4500| 10500|
|PU_CLERK |Purchasing Clerk | 2500| 5500|
|PU_MAN |Purchasing Manager | 8000| 15000|
|SA_MAN |Sales Manager | 10000| 20080|
|SA_REP |Sales Representative | 6000| 12008|
|SH_CLERK |Shipping Clerk | 2500| 5500|
|ST_CLERK |Stock Clerk | 2008| 5000|
|ST_MAN |Stock Manager | 5500| 8500|
+----------+-------------------------------+----------+----------+Two things are interesting.
First, the generated SELECT statement lists all columns, even if no column was defined in the query on program line 65.
Second, the output is formatted nicely. Where did this happen? On line 59 the query is executed and the result is saved in the local variable named result. This is a result set and contains all rows. For example, you may get the number of rows via result.size(), as on line 60. I may also loop through the result set and do whatever I want. In this case, I just used a convenience function format to format the result set as text. There are other convenience functions such as formatCSV, formatHTML, formatJSON or formatXML. You may guess by the name what they are doing. Nice!
SQL Trace Output
The Java program produces a SQL Trace file by default. See program line 40. Here’s the relevant tkprof excerpt:
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.03 0.18 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 2 0 19
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.03 0.18 0 2 0 19
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 133
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
19 19 19 TABLE ACCESS BY INDEX ROWID JOBS (cr=2 pr=0 pw=0 time=45 us starts=1 cost=2 size=627 card=19)
19 19 19 INDEX FULL SCAN JOB_ID_PK (cr=1 pr=0 pw=0 time=18 us starts=1 cost=1 size=0 card=19)(object id 78619)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
SQL*Net message from client 1 0.10 0.10Interesting is line 5 of the output. There was just one fetch to retrieve 19 rows. A default configuration of the JDBC driver would have caused two fetches. Our configuration on program line 28 worked. All data fetched in a single network roundtrip.
8. Using Joins & Aggregations
In the next example we query the salaries per location. The idea is to look at a JOOQ query with joins and aggregations.
JOOQ Query
On lines 6-8, you see how aggregate functions are used in JOOQ and how to define an alias for the resulting column.
Line 10 is interesting. It defines the join using the onKey function. This function requires a parameter when multiple join paths are possible. In this case EMPLOYEE_V and DEPARTMENTS_V may be joined either via DEPARTMENTS_V.MANAGER_ID or via EMPLOYEES_V.DEPARTMENT_ID. In this case we defined the latter.
On line 11 the onKey function has no parameters, since only one join path exists to LOCATIONS. This clearly shows how JOOQ uses our referential integrity constraints on the view-API to build the query. The idea is similar to a NATURAL JOIN, but the implementation is better since it relies on constraints and not naming conventions. I already miss this feature in SQL.
The use of the functions groupBy and orderBy on line 14 and 15 should be self-explanatory.
private static void querySalariesPerLocation() {
final ResultQuery<?> query = ctx
.select(REGIONS_V.REGION_NAME,
COUNTRIES_V.COUNTRY_NAME,
LOCATIONS_V.CITY,
count().as("employees"),
sum(EMPLOYEES_V.SALARY).as("sum_salaray"),
max(EMPLOYEES_V.SALARY).as("max_salary"))
.from(EMPLOYEES_V)
.join(DEPARTMENTS_V).onKey(EMPLOYEES_V.DEPARTMENT_ID)
.join(LOCATIONS_V).onKey()
.join(COUNTRIES_V).onKey()
.join(REGIONS_V).onKey()
.groupBy(REGIONS_V.REGION_NAME, COUNTRIES_V.COUNTRY_NAME, LOCATIONS_V.CITY)
.orderBy(REGIONS_V.REGION_NAME, COUNTRIES_V.COUNTRY_NAME, LOCATIONS_V.CITY);
fetchAndPrint("Salaries Per Location", query);
}SQL Query & Result
No surprises. The query looks as expected.
Salaries Per Location:
select
"HR"."REGIONS_V"."REGION_NAME",
"HR"."COUNTRIES_V"."COUNTRY_NAME",
"HR"."LOCATIONS_V"."CITY",
count(*) "employees",
sum("HR"."EMPLOYEES_V"."SALARY") "sum_salaray",
max("HR"."EMPLOYEES_V"."SALARY") "max_salary"
from "HR"."EMPLOYEES_V"
join "HR"."DEPARTMENTS_V"
on "HR"."EMPLOYEES_V"."DEPARTMENT_ID" = "HR"."DEPARTMENTS_V"."DEPARTMENT_ID"
join "HR"."LOCATIONS_V"
on "HR"."DEPARTMENTS_V"."LOCATION_ID" = "HR"."LOCATIONS_V"."LOCATION_ID"
join "HR"."COUNTRIES_V"
on "HR"."LOCATIONS_V"."COUNTRY_ID" = "HR"."COUNTRIES_V"."COUNTRY_ID"
join "HR"."REGIONS_V"
on "HR"."COUNTRIES_V"."REGION_ID" = "HR"."REGIONS_V"."REGION_ID"
group by
"HR"."REGIONS_V"."REGION_NAME",
"HR"."COUNTRIES_V"."COUNTRY_NAME",
"HR"."LOCATIONS_V"."CITY"
order by
"HR"."REGIONS_V"."REGION_NAME",
"HR"."COUNTRIES_V"."COUNTRY_NAME",
"HR"."LOCATIONS_V"."CITY"
Salaries Per Location result (7 rows):
+-----------+------------------------+-------------------+---------+-----------+----------+
|REGION_NAME|COUNTRY_NAME |CITY |employees|sum_salaray|max_salary|
+-----------+------------------------+-------------------+---------+-----------+----------+
|Americas |Canada |Toronto | 2| 19000| 13000|
|Americas |United States of America|Seattle | 18| 159216| 24000|
|Americas |United States of America|South San Francisco| 45| 156400| 8200|
|Americas |United States of America|Southlake | 5| 28800| 9000|
|Europe |Germany |Munich | 1| 10000| 10000|
|Europe |United Kingdom |London | 1| 6500| 6500|
|Europe |United Kingdom |Oxford | 34| 304500| 14000|
+-----------+------------------------+-------------------+---------+-----------+----------+SQL Trace Output
In the tkprof output we see that parsing took more than a second. This is a bit too long for this kind of query. However, that is not a problem of JOOQ. Beside that, the output looks good. Single network roundtrip as expected.
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.24 1.09 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 22 0 7
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.25 1.09 0 22 0 7
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 133
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
7 7 7 SORT GROUP BY (cr=24 pr=0 pw=0 time=8817 us starts=1 cost=12 size=5512 card=106)
106 106 106 HASH JOIN (cr=24 pr=0 pw=0 time=8745 us starts=1 cost=11 size=5512 card=106)
27 27 27 MERGE JOIN (cr=16 pr=0 pw=0 time=294 us starts=1 cost=8 size=1215 card=27)
3 3 3 TABLE ACCESS BY INDEX ROWID REGIONS (cr=2 pr=0 pw=0 time=43 us starts=1 cost=2 size=56 card=4)
3 3 3 INDEX FULL SCAN REG_ID_PK (cr=1 pr=0 pw=0 time=11 us starts=1 cost=1 size=0 card=4)(object id 78609)
27 27 27 SORT JOIN (cr=14 pr=0 pw=0 time=251 us starts=3 cost=6 size=837 card=27)
27 27 27 VIEW VW_GBF_23 (cr=14 pr=0 pw=0 time=328 us starts=1 cost=5 size=837 card=27)
27 27 27 NESTED LOOPS (cr=14 pr=0 pw=0 time=325 us starts=1 cost=5 size=999 card=27)
27 27 27 MERGE JOIN (cr=10 pr=0 pw=0 time=238 us starts=1 cost=5 size=594 card=27)
19 19 19 TABLE ACCESS BY INDEX ROWID LOCATIONS (cr=2 pr=0 pw=0 time=32 us starts=1 cost=2 size=345 card=23)
19 19 19 INDEX FULL SCAN LOC_ID_PK (cr=1 pr=0 pw=0 time=26 us starts=1 cost=1 size=0 card=23)(object id 78613)
27 27 27 SORT JOIN (cr=8 pr=0 pw=0 time=189 us starts=19 cost=3 size=189 card=27)
27 27 27 VIEW index$_join$_013 (cr=8 pr=0 pw=0 time=163 us starts=1 cost=2 size=189 card=27)
27 27 27 HASH JOIN (cr=8 pr=0 pw=0 time=162 us starts=1)
27 27 27 INDEX FAST FULL SCAN DEPT_ID_PK (cr=4 pr=0 pw=0 time=35 us starts=1 cost=1 size=189 card=27)(object id 78616)
27 27 27 INDEX FAST FULL SCAN DEPT_LOCATION_IX (cr=4 pr=0 pw=0 time=15 us starts=1 cost=1 size=189 card=27)(object id 78631)
27 27 27 INDEX UNIQUE SCAN COUNTRY_C_ID_PK (cr=4 pr=0 pw=0 time=20 us starts=27 cost=0 size=15 card=1)(object id 78611)
107 107 107 TABLE ACCESS FULL EMPLOYEES (cr=6 pr=0 pw=0 time=35 us starts=1 cost=3 size=749 card=107)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
PGA memory operation 1 0.00 0.00
SQL*Net message from client 1 0.01 0.019. Using Bind Variables
Parsing can be costly, as we have seen in the previous example. Using bind variables can reduce parsing. In this case I’d like to see how I can avoid hard- and soft-parsing. See Oracle FAQs for good parsing definitions.
JOOQ Query
JOOQ automatically creates bind variables for the usages of fromSalary and toSalary on line 23. This means that JOOQ eliminates unnecessary hard parses by design. To eliminate unnecessary soft-parses we have to ensure that the Java statement behind the scenes is not closed. JOOQ provides the keepStatement function for that purpose as used on line 25. When using this function we are responsible to close the statement. We do so on line 7.
We call the query twice. See lines 36 and 37. On the first call, the bind variables are set automatically by JOOQ when building the preparedQuery. On subsequent calls the preparedQuery is reused and its bind variable values are changed. See line 27 and 28. Fetching and printing works as for the other JOOQ queries. The only difference is, that the statement is not closed after the last row is fetched.
public class Main {
private static ResultQuery<?> preparedQuery;
(...)
private static void closeCtx() throws SQLException {
disableSqlTrace();
if (preparedQuery != null) {
preparedQuery.close();
}
ctx.close();
}
(...)
private static void queryEmployeesInSalaryRange(BigDecimal fromSalary, BigDecimal toSalary) {
if (preparedQuery == null) {
preparedQuery = ctx
.select(JOBS_V.JOB_TITLE,
EMPLOYEES_V.LAST_NAME,
EMPLOYEES_V.FIRST_NAME,
EMPLOYEES_V.SALARY,
JOBS_V.MIN_SALARY,
JOBS_V.MAX_SALARY)
.from(EMPLOYEES_V)
.join(JOBS_V).onKey()
.where(EMPLOYEES_V.SALARY.between(fromSalary, toSalary))
.orderBy(EMPLOYEES_V.SALARY.desc())
.keepStatement(true);
} else {
preparedQuery.bind(1, fromSalary);
preparedQuery.bind(2, toSalary);
}
fetchAndPrint("Employees in Salary Range", preparedQuery);
}
(...)
public static void main(String[] args) throws SQLException {
initCtx(true);
(...)
queryEmployeesInSalaryRange(BigDecimal.valueOf(13000), BigDecimal.valueOf(100000));
queryEmployeesInSalaryRange(BigDecimal.valueOf(10000), BigDecimal.valueOf(13000));
closeCtx();
}
}SQL Query & Result
We are executing the query twice. Hence we see two output sets.
On lines 13/45, you see the bind variable placeholders (?).
On lines 17-18/49-50, you see the values of the bind variables.
Employees in Salary Range:
select
"HR"."JOBS_V"."JOB_TITLE",
"HR"."EMPLOYEES_V"."LAST_NAME",
"HR"."EMPLOYEES_V"."FIRST_NAME",
"HR"."EMPLOYEES_V"."SALARY",
"HR"."JOBS_V"."MIN_SALARY",
"HR"."JOBS_V"."MAX_SALARY"
from "HR"."EMPLOYEES_V"
join "HR"."JOBS_V"
on "HR"."EMPLOYEES_V"."JOB_ID" = "HR"."JOBS_V"."JOB_ID"
where "HR"."EMPLOYEES_V"."SALARY" between ? and ?
order by "HR"."EMPLOYEES_V"."SALARY" desc
Employees in Salary Range binds:
:1 = 13000
:2 = 100000
Employees in Salary Range result (6 rows):
+-----------------------------+---------+----------+------+----------+----------+
|JOB_TITLE |LAST_NAME|FIRST_NAME|SALARY|MIN_SALARY|MAX_SALARY|
+-----------------------------+---------+----------+------+----------+----------+
|President |King |Steven | 24000| 20080| 40000|
|Administration Vice President|Kochhar |Neena | 17000| 15000| 30000|
|Administration Vice President|De Haan |Lex | 17000| 15000| 30000|
|Sales Manager |Russell |John | 14000| 10000| 20080|
|Sales Manager |Partners |Karen | 13500| 10000| 20080|
|Marketing Manager |Hartstein|Michael | 13000| 9000| 15000|
+-----------------------------+---------+----------+------+----------+----------+
Employees in Salary Range:
select
"HR"."JOBS_V"."JOB_TITLE",
"HR"."EMPLOYEES_V"."LAST_NAME",
"HR"."EMPLOYEES_V"."FIRST_NAME",
"HR"."EMPLOYEES_V"."SALARY",
"HR"."JOBS_V"."MIN_SALARY",
"HR"."JOBS_V"."MAX_SALARY"
from "HR"."EMPLOYEES_V"
join "HR"."JOBS_V"
on "HR"."EMPLOYEES_V"."JOB_ID" = "HR"."JOBS_V"."JOB_ID"
where "HR"."EMPLOYEES_V"."SALARY" between ? and ?
order by "HR"."EMPLOYEES_V"."SALARY" desc
Employees in Salary Range binds:
:1 = 10000
:2 = 13000
Employees in Salary Range result (14 rows):
+-------------------------------+---------+----------+------+----------+----------+
|JOB_TITLE |LAST_NAME|FIRST_NAME|SALARY|MIN_SALARY|MAX_SALARY|
+-------------------------------+---------+----------+------+----------+----------+
|Marketing Manager |Hartstein|Michael | 13000| 9000| 15000|
|Finance Manager |Greenberg|Nancy | 12008| 8200| 16000|
|Accounting Manager |Higgins |Shelley | 12008| 8200| 16000|
|Sales Manager |Errazuriz|Alberto | 12000| 10000| 20080|
|Sales Representative |Ozer |Lisa | 11500| 6000| 12008|
|Purchasing Manager |Raphaely |Den | 11000| 8000| 15000|
|Sales Manager |Cambrault|Gerald | 11000| 10000| 20080|
|Sales Representative |Abel |Ellen | 11000| 6000| 12008|
|Sales Representative |Vishney |Clara | 10500| 6000| 12008|
|Sales Manager |Zlotkey |Eleni | 10500| 10000| 20080|
|Sales Representative |Tucker |Peter | 10000| 6000| 12008|
|Sales Representative |Bloom |Harrison | 10000| 6000| 12008|
|Public Relations Representative|Baer |Hermann | 10000| 4500| 10500|
|Sales Representative |King |Janette | 10000| 6000| 12008|
+-------------------------------+---------+----------+------+----------+----------+SQL Trace Output
The tkprof excerpt on line 4 shows that the query is executed twice. Line 3 reveals that the query is parsed only once. The total of 20 rows are read in two network roundtrips. That’s perfect.
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 2 0.01 0.05 0 0 0 0
Fetch 2 0.00 0.00 0 16 0 20
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 5 0.01 0.05 0 16 0 20
Misses in library cache during parse: 1
Misses in library cache during execute: 1
Optimizer mode: ALL_ROWS
Parsing user id: 133
Number of plan statistics captured: 2
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
6 10 14 SORT ORDER BY (cr=8 pr=0 pw=0 time=160 us starts=1 cost=7 size=366 card=6)
6 10 14 FILTER (cr=8 pr=0 pw=0 time=156 us starts=1)
6 10 14 MERGE JOIN (cr=8 pr=0 pw=0 time=153 us starts=1 cost=6 size=366 card=6)
16 16 17 TABLE ACCESS BY INDEX ROWID JOBS (cr=2 pr=0 pw=0 time=38 us starts=1 cost=2 size=627 card=19)
16 16 17 INDEX FULL SCAN JOB_ID_PK (cr=1 pr=0 pw=0 time=20 us starts=1 cost=1 size=0 card=19)(object id 78619)
6 10 14 SORT JOIN (cr=6 pr=0 pw=0 time=94 us starts=16 cost=4 size=168 card=6)
6 10 14 TABLE ACCESS FULL EMPLOYEES (cr=6 pr=0 pw=0 time=68 us starts=1 cost=3 size=168 card=6)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 2 0.00 0.00
SQL*Net message from client 2 0.00 0.0010. Run a Top N Query
In the next example we query the 4 employees with the lowest salary along with some general salary information. It’ll be interesting to see if JOOQ uses Oracle’s native top-n query syntax.
JOOQ Query
On line 8 we see that JOOQ has no problems dealing with analytic functions.
On line 14 the top n query is defined. Limit the result to 4 rows with ties, this means rows with the same order by values are considered as well.
private static void queryTopBadEarners() {
final ResultQuery<?> query = ctx
.select(JOBS_V.JOB_TITLE,
EMPLOYEES_V.LAST_NAME,
EMPLOYEES_V.FIRST_NAME,
EMPLOYEES_V.HIRE_DATE,
EMPLOYEES_V.SALARY,
avg(EMPLOYEES_V.SALARY).over().partitionBy(EMPLOYEES_V.JOB_ID).as("avg_salary"),
JOBS_V.MIN_SALARY,
JOBS_V.MAX_SALARY)
.from(EMPLOYEES_V)
.join(JOBS_V).onKey()
.orderBy(EMPLOYEES_V.SALARY)
.limit(4).withTies();
fetchAndPrint("Top 4 Bad Earners", query);
}SQL Query & Result
The query crafted by JOOQ is a native Oracle top n query. See line 16. Very good.
Interesting is, that JOOQ also creates a bind variable for the literal 4. This could be good or bad. If you want to use a literal instead of a bind variable, you can simply use inline(4) instead of 4. The default behaviour of JOOQ reminds a little of CURSOR_SHARING=FORCE. But since you may control the behaviour on statement level, I think it is a good and sensible default.
We got a result of 5 rows, because Landry and Gee both have a salary of 2400. That’s the result of WITH TIES.
Top 4 Bad Earners:
select
"HR"."JOBS_V"."JOB_TITLE",
"HR"."EMPLOYEES_V"."LAST_NAME",
"HR"."EMPLOYEES_V"."FIRST_NAME",
"HR"."EMPLOYEES_V"."HIRE_DATE",
"HR"."EMPLOYEES_V"."SALARY",
avg("HR"."EMPLOYEES_V"."SALARY") over (partition by "HR"."EMPLOYEES_V"."JOB_ID") "avg_salary",
"HR"."JOBS_V"."MIN_SALARY",
"HR"."JOBS_V"."MAX_SALARY"
from "HR"."EMPLOYEES_V"
join "HR"."JOBS_V"
on "HR"."EMPLOYEES_V"."JOB_ID" = "HR"."JOBS_V"."JOB_ID"
order by "HR"."EMPLOYEES_V"."SALARY"
fetch next ? rows with ties
Top 4 Bad Earners binds:
:1 = 4
Top 4 Bad Earners result (5 rows):
+-----------+----------+----------+----------+------+----------+----------+----------+
|JOB_TITLE |LAST_NAME |FIRST_NAME|HIRE_DATE |SALARY|avg_salary|MIN_SALARY|MAX_SALARY|
+-----------+----------+----------+----------+------+----------+----------+----------+
|Stock Clerk|Olson |TJ |2007-04-10| 2100| 2785| 2008| 5000|
|Stock Clerk|Markle |Steven |2008-03-08| 2200| 2785| 2008| 5000|
|Stock Clerk|Philtanker|Hazel |2008-02-06| 2200| 2785| 2008| 5000|
|Stock Clerk|Landry |James |2007-01-14| 2400| 2785| 2008| 5000|
|Stock Clerk|Gee |Ki |2007-12-12| 2400| 2785| 2008| 5000|
+-----------+----------+----------+----------+------+----------+----------+----------+SQL Trace Output
The tkprof excerpt looks good. Good performance, single network roundtrip.
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 8 0 5
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.00 0.01 0 8 0 5
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 133
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
5 5 5 VIEW (cr=8 pr=0 pw=0 time=335 us starts=1 cost=7 size=14124 card=107)
11 11 11 WINDOW SORT PUSHED RANK (cr=8 pr=0 pw=0 time=326 us starts=1 cost=7 size=7383 card=107)
107 107 107 WINDOW BUFFER (cr=8 pr=0 pw=0 time=260 us starts=1 cost=7 size=7383 card=107)
107 107 107 MERGE JOIN (cr=8 pr=0 pw=0 time=634 us starts=1 cost=6 size=7383 card=107)
19 19 19 TABLE ACCESS BY INDEX ROWID JOBS (cr=2 pr=0 pw=0 time=42 us starts=1 cost=2 size=627 card=19)
19 19 19 INDEX FULL SCAN JOB_ID_PK (cr=1 pr=0 pw=0 time=30 us starts=1 cost=1 size=0 card=19)(object id 78619)
107 107 107 SORT JOIN (cr=6 pr=0 pw=0 time=97 us starts=19 cost=4 size=3852 card=107)
107 107 107 TABLE ACCESS FULL EMPLOYEES (cr=6 pr=0 pw=0 time=28 us starts=1 cost=3 size=3852 card=107)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
SQL*Net message from client 1 0.01 0.0111. Using Row Pattern Matching
What about match_recognize, does JOOQ support that? No, not currently. JOOQ has some limitations regarding SQL support. match_recognize is one and the model_clause is another. This is something to be expected, since the SQL grammar is still evolving. However, the question is, how do we deal with queries that must apply some SQL which cannot be created by JOOQ’s query builder? The solution is simple. We simply pass the pure SQL to JOOQ.
JOOQ Query
There are other ways to produce the same result without using match_recognize. However, if you would like to use JOOQ and match_recognize then you have to build the SQL yourself and pass it to JOOQ as on line 58.
It’s sad that Java still does not support multiline strings. The code is much simpler in other JVM languages that support multiline strings, such as Scala, Groovy, Kotlin or Xtend.
private static void queryBestPayedNewEntries() {
// using {{\\??\\}} instead of "??" to ensure JDBC does not interpret questions marks as a bind variable placeholders
// see https://docs.oracle.com/en/database/oracle/oracle-database/18/jjdbc/JDBC-reference-information.html#GUID-3454411C-5F24-4D46-83A9-5DA0BA704F5D
// documentation is wrong, escaping is required.
StringBuffer sb = new StringBuffer();
sb.append("WITH\n");
sb.append(" base AS (\n");
sb.append(" SELECT emp.employee_id,\n");
sb.append(" emp.last_name,\n");
sb.append(" emp.first_name,\n");
sb.append(" job.job_title,\n");
sb.append(" jhist.start_date,\n");
sb.append(" emp.salary\n");
sb.append(" FROM hr.employees_v emp\n");
sb.append(" JOIN hr.job_history_v jhist\n");
sb.append(" ON jhist.employee_id = emp.employee_id\n");
sb.append(" JOIN hr.jobs_v job\n");
sb.append(" ON job.job_id = jhist.job_id\n");
sb.append(" UNION\n");
sb.append(" SELECT emp.employee_id,\n");
sb.append(" emp.last_name,\n");
sb.append(" emp.first_name,\n");
sb.append(" job.job_title,\n");
sb.append(" emp.hire_date AS start_date,\n");
sb.append(" emp.salary\n");
sb.append(" FROM hr.employees_v emp\n");
sb.append(" JOIN hr.jobs_v job\n");
sb.append(" ON job.job_id = emp.job_id\n");
sb.append(" ),\n");
sb.append(" aggr AS (\n");
sb.append(" SELECT employee_id,\n");
sb.append(" last_name,\n");
sb.append(" first_name,\n");
sb.append(" job_title,\n");
sb.append(" MAX(start_date) AS start_date,\n");
sb.append(" salary,\n");
sb.append(" MAX(salary) OVER (PARTITION BY job_title ORDER BY MAX(start_date)\n");
sb.append(" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS max_salary\n");
sb.append(" FROM base\n");
sb.append(" GROUP BY employee_id, last_name, first_name, job_title, salary\n");
sb.append(" )\n");
sb.append("SELECT job_title, start_date, last_name, first_name, salary\n");
sb.append(" FROM aggr MATCH_RECOGNIZE (\n");
sb.append(" PARTITION BY job_title\n");
sb.append(" ORDER BY start_date\n");
sb.append(" MEASURES LAST(employee_id) AS employee_id,\n");
sb.append(" LAST(last_name) AS last_name,\n");
sb.append(" LAST(first_name) AS first_name,\n");
sb.append(" LAST(start_date) AS start_date,\n");
sb.append(" LAST(salary) AS salary\n");
sb.append(" ONE ROW PER MATCH\n");
sb.append(" PATTERN((strt down*){{\\??\\}} up)\n");
sb.append(" DEFINE strt AS salary = MAX(max_salary),\n");
sb.append(" down AS salary < MAX(max_salary),\n");
sb.append(" up AS salary = MAX(max_salary)\n");
sb.append(" )\n");
sb.append(" ORDER BY job_title, start_date");
final ResultQuery<Record> query = ctx.resultQuery(sb.toString());
fetchAndPrint("Best Payed New Entries", query);
}SQL Query & Result
On line 49 you see that {\??\} is used instead of ??. This is a necessity for the JDBC driver. Otherwise, the driver would expect bind variables for these question marks. All Java-based tools such as SQL Developer and SQLcl do have the same “problem”.
Best Payed New Entries:
WITH
base AS (
SELECT emp.employee_id,
emp.last_name,
emp.first_name,
job.job_title,
jhist.start_date,
emp.salary
FROM hr.employees_v emp
JOIN hr.job_history_v jhist
ON jhist.employee_id = emp.employee_id
JOIN hr.jobs_v job
ON job.job_id = jhist.job_id
UNION
SELECT emp.employee_id,
emp.last_name,
emp.first_name,
job.job_title,
emp.hire_date AS start_date,
emp.salary
FROM hr.employees_v emp
JOIN hr.jobs_v job
ON job.job_id = emp.job_id
),
aggr AS (
SELECT employee_id,
last_name,
first_name,
job_title,
MAX(start_date) AS start_date,
salary,
MAX(salary) OVER (PARTITION BY job_title ORDER BY MAX(start_date)
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS max_salary
FROM base
GROUP BY employee_id, last_name, first_name, job_title, salary
)
SELECT job_title, start_date, last_name, first_name, salary
FROM aggr MATCH_RECOGNIZE (
PARTITION BY job_title
ORDER BY start_date
MEASURES LAST(employee_id) AS employee_id,
LAST(last_name) AS last_name,
LAST(first_name) AS first_name,
LAST(start_date) AS start_date,
LAST(salary) AS salary
ONE ROW PER MATCH
PATTERN((strt down*){\??\} up)
DEFINE strt AS salary = MAX(max_salary),
down AS salary < MAX(max_salary),
up AS salary = MAX(max_salary)
)
ORDER BY job_title, start_date
Best Payed New Entries result (25 rows):
+-------------------------------+----------+---------+----------+------+
|JOB_TITLE |START_DATE|LAST_NAME|FIRST_NAME|SALARY|
+-------------------------------+----------+---------+----------+------+
|Accountant |2002-08-16|Faviet |Daniel | 9000|
|Accounting Manager |2001-10-28|Kochhar |Neena | 17000|
|Administration Assistant |2003-09-17|Whalen |Jennifer | 4400|
|Administration Vice President |2001-01-13|De Haan |Lex | 17000|
|Administration Vice President |2005-09-21|Kochhar |Neena | 17000|
|Finance Manager |2002-08-17|Greenberg|Nancy | 12008|
|Human Resources Representative |2002-06-07|Mavris |Susan | 6500|
|Marketing Manager |2004-02-17|Hartstein|Michael | 13000|
|Marketing Representative |2004-02-17|Hartstein|Michael | 13000|
|President |2003-06-17|King |Steven | 24000|
|Programmer |2001-01-13|De Haan |Lex | 17000|
|Public Accountant |1997-09-21|Kochhar |Neena | 17000|
|Public Relations Representative|2002-06-07|Baer |Hermann | 10000|
|Purchasing Clerk |2003-05-18|Khoo |Alexander | 3100|
|Purchasing Manager |2002-12-07|Raphaely |Den | 11000|
|Sales Manager |2004-10-01|Russell |John | 14000|
|Sales Representative |2004-01-30|King |Janette | 10000|
|Sales Representative |2004-05-11|Abel |Ellen | 11000|
|Sales Representative |2005-03-11|Ozer |Lisa | 11500|
|Shipping Clerk |2004-01-27|Sarchand |Nandita | 4200|
|Stock Clerk |2003-07-14|Ladwig |Renske | 3600|
|Stock Clerk |2006-03-24|Raphaely |Den | 11000|
|Stock Manager |2003-05-01|Kaufling |Payam | 7900|
|Stock Manager |2004-07-18|Weiss |Matthew | 8000|
|Stock Manager |2005-04-10|Fripp |Adam | 8200|
+-------------------------------+----------+---------+----------+------+SQL Trace Output
The tkprof excerpt shows that most of the time is spent parsing the query, but it is still fast. All 25 result rows are fetched in a single network roundtrip.
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.20 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 22 0 25
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.01 0.20 0 22 0 25
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 133
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
25 25 25 SORT ORDER BY (cr=22 pr=0 pw=0 time=1965 us starts=1 cost=22 size=7839 card=117)
25 25 25 VIEW (cr=22 pr=0 pw=0 time=2016 us starts=1 cost=21 size=7839 card=117)
25 25 25 MATCH RECOGNIZE SORT (cr=22 pr=0 pw=0 time=2016 us starts=1 cost=21 size=9360 card=117)
115 115 115 VIEW (cr=22 pr=0 pw=0 time=1905 us starts=1 cost=20 size=9360 card=117)
115 115 115 WINDOW SORT (cr=22 pr=0 pw=0 time=1904 us starts=1 cost=20 size=9360 card=117)
115 115 115 HASH GROUP BY (cr=22 pr=0 pw=0 time=1718 us starts=1 cost=20 size=9360 card=117)
116 116 116 VIEW (cr=22 pr=0 pw=0 time=385 us starts=1 cost=18 size=9360 card=117)
116 116 116 SORT UNIQUE (cr=22 pr=0 pw=0 time=384 us starts=1 cost=18 size=7879 card=117)
117 117 117 UNION-ALL (cr=22 pr=0 pw=0 time=213 us starts=1)
10 10 10 HASH JOIN (cr=14 pr=0 pw=0 time=210 us starts=1 cost=9 size=710 card=10)
10 10 10 NESTED LOOPS (cr=8 pr=0 pw=0 time=126 us starts=1 cost=9 size=710 card=10)
10 10 10 NESTED LOOPS (cr=8 pr=0 pw=0 time=116 us starts=1)
10 10 10 STATISTICS COLLECTOR (cr=8 pr=0 pw=0 time=115 us starts=1)
10 10 10 MERGE JOIN (cr=8 pr=0 pw=0 time=121 us starts=1 cost=6 size=480 card=10)
10 10 10 TABLE ACCESS BY INDEX ROWID JOB_HISTORY (cr=2 pr=0 pw=0 time=34 us starts=1 cost=2 size=210 card=10)
10 10 10 INDEX FULL SCAN JHIST_JOB_IX (cr=1 pr=0 pw=0 time=24 us starts=1 cost=1 size=0 card=10)(object id 78632)
10 10 10 SORT JOIN (cr=6 pr=0 pw=0 time=72 us starts=10 cost=4 size=513 card=19)
19 19 19 TABLE ACCESS FULL JOBS (cr=6 pr=0 pw=0 time=42 us starts=1 cost=3 size=513 card=19)
0 0 0 INDEX UNIQUE SCAN EMP_EMP_ID_PK (cr=0 pr=0 pw=0 time=0 us starts=0)(object id 78622)
0 0 0 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=0 pr=0 pw=0 time=0 us starts=0 cost=3 size=23 card=1)
107 107 107 TABLE ACCESS FULL EMPLOYEES (cr=6 pr=0 pw=0 time=11 us starts=1 cost=3 size=2461 card=107)
107 107 107 MERGE JOIN (cr=8 pr=0 pw=0 time=366 us starts=1 cost=6 size=7169 card=107)
19 19 19 TABLE ACCESS BY INDEX ROWID JOBS (cr=2 pr=0 pw=0 time=27 us starts=1 cost=2 size=513 card=19)
19 19 19 INDEX FULL SCAN JOB_ID_PK (cr=1 pr=0 pw=0 time=5 us starts=1 cost=1 size=0 card=19)(object id 78619)
107 107 107 SORT JOIN (cr=6 pr=0 pw=0 time=67 us starts=19 cost=4 size=4280 card=107)
107 107 107 TABLE ACCESS FULL EMPLOYEES (cr=6 pr=0 pw=0 time=7 us starts=1 cost=3 size=4280 card=107)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
PGA memory operation 5 0.00 0.00
SQL*Net message from client 1 0.01 0.0112. Conclusion
A view-API has a value. You can change the physical data model and keep the existing view layer compatible for the consuming applications. This makes the database application independent, at least to a certain extent. That’s a great value when you think of testing interfaces or releasing new versions. Building an initial 1:1 view-API is no big deal, especially since it can be generated. The maintenance costs for such a view-API depend on many things. But I can’t imagine a scenario that isn’t worth it.
I was positively surprised by the feature richness and good usability of JOOQ. Things like the deep data model awareness including referential integrity constraints to make joins simpler and less error-prone are impressive. Ok, the DSL needs some getting used to, but the excellent documentation helps a lot. Although I have only scratched the surface of JOOQ, I am convinced that it is very well suited for developing high-performing PinkDB applications. Because JOOQ developers have control over the SQL statements sent to the database.
1 Comment
Thanks a lot for this writeup. I’m glad to hear that you found using jOOQ so straightforward.
Interesting hint about jOOQ’s behaviour being akin to CURSOR_SHARING=FORCE. The reason for the current default is obvious: jOOQ cannot distinguish between what reads as a constant literal (i.e. a literal embedded in the jOOQ API) and a variable (i.e. something that has been previously assigned to a local variable). While the difference is clear to the reader of Java code, behind the scenes, it’s all the same jOOQ expression tree.
However, I can see how the value in the LIMIT clause could profit from being inlined by default and made a bind parameter only explicitly by using DSL.val() (unlike OFFSET, which should definitely be a bind parameter by default). I’ve added a feature request to add a setting that would inline the LIMIT value by default: https://github.com/jOOQ/jOOQ/issues/7720