

Using the database as a persistence layer only is an anti-pattern. Praful Todkar applies this anti-pattern in How to extract a data-rich service from a monolith. Martin Fowler reviewed this article and published it on his website. Hence it is highly visible. I generally agree with the approach. However, I cannot agree with the implementation regarding the database interaction. Based on the referenced article, I will point out the issues and suggest solutions.
Join and Aggregation Logic
In the second step – after extracting product pricing into a dedicated service – the refactored class CategoryPriceRange looks as follows:
public CategoryPriceRange getPriceRangeFor(Category category) {
List<CoreProduct> products = coreProductService.getActiveProductsFor(category);
List<ProductPrice> productPrices = productPriceRepository.getProductPricesFor(mapCoreProductToSku(products));
Price maxPrice = null;
Price minPrice = null;
for (ProductPrice productPrice : productPrices) {
Price currentProductPrice = calculatePriceFor(productPrice);
if (maxPrice == null || currentProductPrice.isGreaterThan(maxPrice)) {
maxPrice = currentProductPrice;
}
if (minPrice == null || currentProductPrice.isLesserThan(minPrice)) {
minPrice = currentProductPrice;
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
private List<Sku> mapCoreProductToSku(List<CoreProduct> coreProducts) {
return coreProducts.stream().map(p -> p.getSku()).collect(Collectors.toList());
}The method getPriceRangeFor returns minPrice and maxPrice for a given product category. Let’s look a bit closer at the implementation of this method.
Line 2 reads all active products. Behind the scenes, this is a single SQL query. The author even recommended pushing the filtering of active products into the database query. So far so good. Let’s say we queried 25 active products this way.
Line 4 reads all prices for the previously queried products. This can be done with a single query (even for large sets with an unbounded number of products) or with a query per product. At this stage, we either issued 2 queries or more likely 26 queries. Basically, the operation on this line is equivalent to a join between Products and ProductPrices. At this interim stage, it is physically one Products table including product price data, but I assume this will change in one of the coming installments.
The next two highlighted lines 11 and 14 show the calculation of minPrice and maxPrice. This is clearly a manually crafted aggregation logic. Databases are really good at aggregating data. So, why reinvent the wheel and make such kind of logic a responsibility of the application? What happens if you need to calculate the average or a percentile?
However, this works technically. However, this approach consumes more resources on the application server and the database server than necessary. This might lead to performance issues and limits the scalability of the application. It’s just about the number of database calls, the code path executed on the servers including OS and last but not least the time spent on the network. See also Toon Koppelaar’s video or slide deck for more information, especially regarding the “living room analogy”.
So my issues are:
1. Joins in the application
2. Aggregation logic in the application
As a consequence, more database calls are necessary to complete the job.
Solution Approach
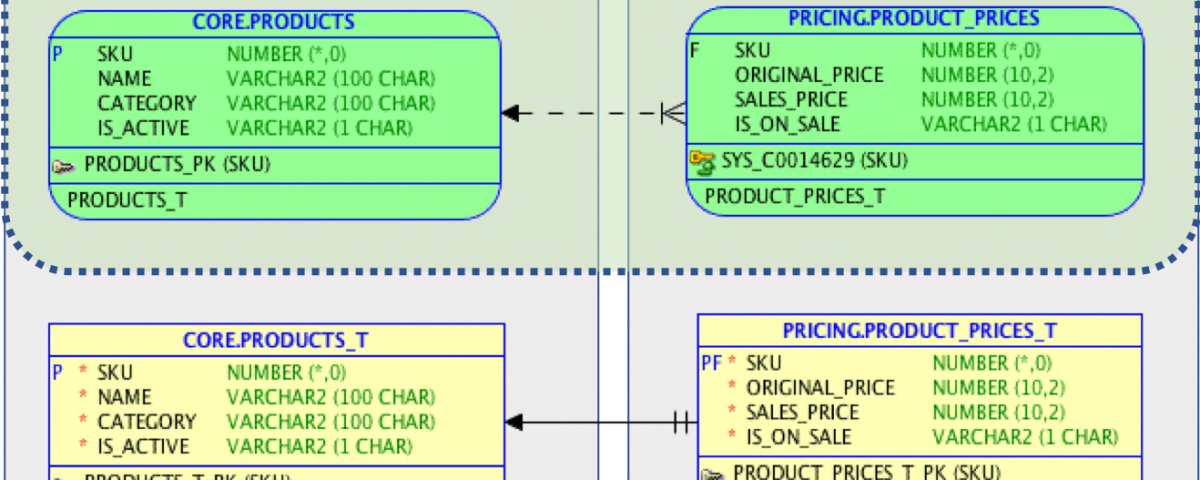
Let’s assume that extracting product pricing into a dedicated service is sensible. In this case, it is reasonable to move the pricing data into a dedicated database schema as well. The next picture shows the schemas, tables and the view layer used as API.
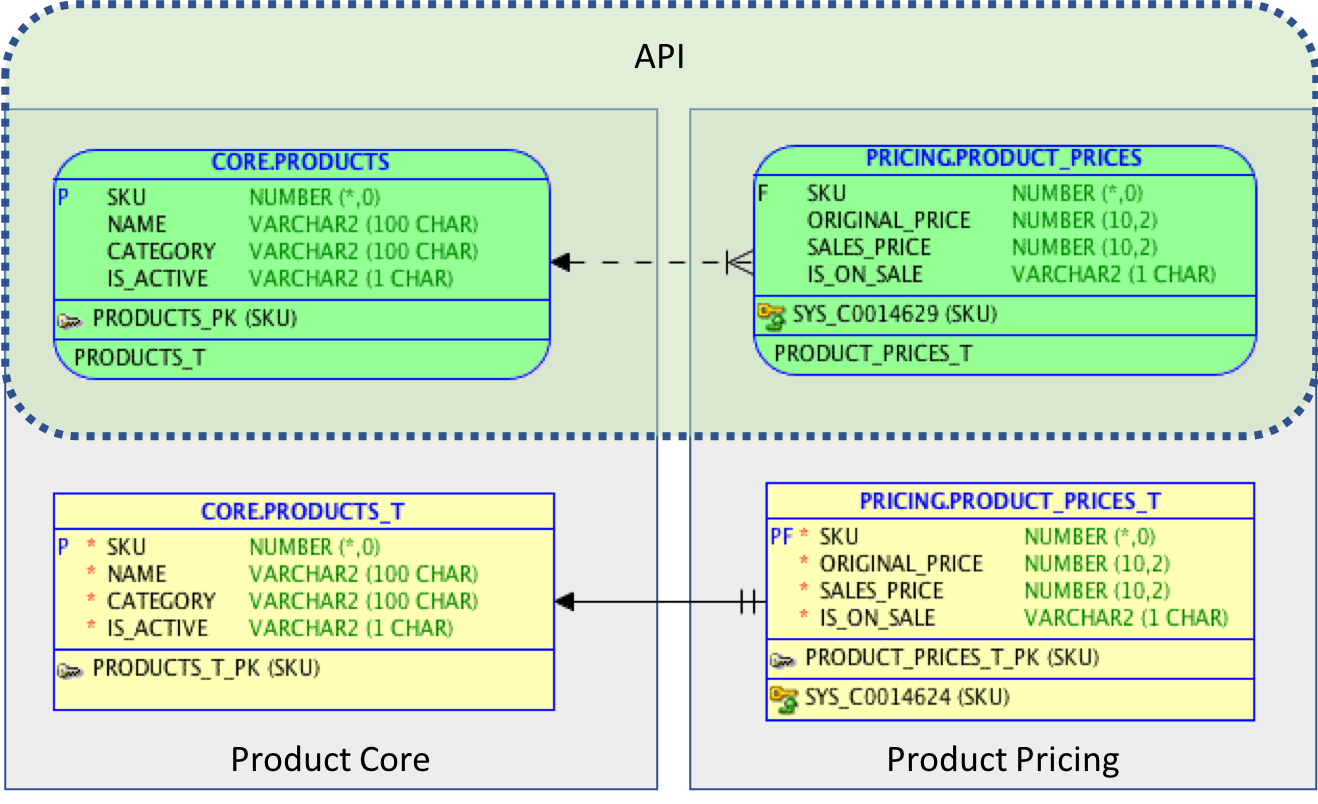
The view layer is the API. It is a 1:1 representation of the underlying tables. But you can imagine that the view layer could be used to either represent the original product structure on the new tables or the new structure based on the original single products table.
The database user connecting from the pricing service to the database gets the following access rights:
- GRANT READ ON core.products
- GRANT SELECT, INSERT, UPDATE, DELETE ON pricing.product_prices
The method getPriceRangeFor is rewritten to return the result of the following query:
SELECT c.category, min(p.sales_price), max(p.sales_price)
FROM core.products c
JOIN pricing.product_prices p
ON p.sku = c.sku
WHERE c.category = ?
GROUP BY c.categoryThis addresses the issues 1 and 2 mentioned above. No joins and aggregations in the application. From a performance point of view, this is the best solution. You get the result with a single call to the database and a single network roundtrip. You use fewer resources on the application server and fewer resources on the database server. Hence you can handle more transactions with the same hardware.
However, from an architectural point of view, this solution introduces the following, additional issues:
3. The schema core and pricing have to be installed in the same database
4. The core database application is used by more than one service
Issue 3 is the price for better performance. Using database links or something similar will technically work, but is for sure less optimal from a performance point of view.
The product service already depends on the core service. Now this dependency is also visible in the database application (database layer). That’s not nice, but not a big issue either.
Conclusion
If you break your monolithic applications into smaller parts to allow teams to control “their own destiny”, then you must be aware that these smaller parts are not independent. Treating the database as a persistence layer only will lead to applications that are mimicking database functionality less efficiently. For small applications, you won’t notice the difference, but you will on a larger scale. The solution is simple. Use the database as a processing engine as recommended by PinkDB and SmartDB.