

In Joining Temporal Intervals I explained how to join multiple temporal tables. The provided solution merges also temporal intervals but – as pointed out in that post – may produce wrong results if the underlying driving table is not gaplessly historized. In this post, I’ll explain how to merge temporal intervals with various data constellations correctly.
You find the scripts to create and populate the tables for scenarios A and B here.
Scenario A – No overlapping intervals
This scenario handles consistent data. This means no overlapping intervals, no duplicate intervals, no including intervals, and no negative intervals (valid_to < valid_from). Here is the content of the example table t1:
SQL> SELECT * FROM t1;
VID OID VALID_FROM VALID_TO C1 C2
---------- ---------- ----------- ----------- ---------- ----------
1 1 01-JAN-2010 31-DEC-2010 A B1
2 1 01-JAN-2011 31-MAR-2011 A B2
3 1 01-JUN-2011 31-JAN-2012 A B2
4 1 01-APR-2012 31-DEC-9999 A B4
5 2 01-JAN-2010 31-JUL-2012 B B1
6 2 01-AUG-2012 31-DEC-9999 B B2
18 4 01-JAN-2010 30-SEP-2011 D D1
19 4 01-OCT-2011 30-SEP-2012 D2
20 4 01-OCT-2012 31-DEC-9999 D D3I’d like to write a query which produces all intervals for the columns OID and C1 honoring gaps in the historization. For OID 1 I expect that records 1 and 2 are merged, but records 3 and 4 are not merged because the intervals are not “connected”. For OID 2 I expected to get a single merged interval. For OID 4 I expect to get 3 records since the records with C1=’D’ are not connected.
So, the following query result is expected:
OID VALID_FROM VALID_TO C1
---------- ----------- ----------- ----------
1 01-JAN-2010 31-MAR-2011 A
1 01-JUN-2011 31-JAN-2012 A
1 01-APR-2012 31-DEC-9999 A
2 01-JAN-2010 31-DEC-9999 B
4 01-JAN-2010 30-SEP-2011 D
4 01-OCT-2011 30-SEP-2012
4 01-OCT-2012 31-DEC-9999 DThe next query produces exactly this result.
WITH
calc_various AS (
-- produces column has_gap with the following meaning:
-- 1: offset > 0 between current and previous record (gap)
-- 0: offset = 0 between current and previous record (no gap)
-- produces column new_group with the following meaning:
-- 1: group-by-columns differ in current and previous record
-- 0: same group-by-columns in current and previous record
SELECT oid,
valid_from,
valid_to,
c1,
c2,
CASE
WHEN LAG(valid_to, 1, valid_from - 1) OVER(
PARTITION BY oid ORDER BY valid_from
) = valid_from - 1 THEN
0
ELSE
1
END AS has_gap,
CASE
WHEN LAG(c1, 1, c1) OVER(
PARTITION BY oid ORDER BY valid_from
) = c1 THEN
0
ELSE
1
END AS new_group
FROM t1
),
calc_group AS (
-- produces column group_no, records with the same group_no
-- are mergeable, group_no is calculated per oid
SELECT oid,
valid_from,
valid_to,
c1,
c2,
SUM(has_gap + new_group) OVER(
PARTITION BY oid ORDER BY oid, valid_from
) AS group_no
FROM calc_various
),
merged AS (
-- produces the final merged result
-- grouping by group_no ensures that gaps are honored
SELECT oid,
MIN(valid_from) AS valid_from,
MAX(valid_to) AS valid_to,
c1
FROM calc_group
GROUP BY oid, c1, group_no
ORDER BY oid, valid_from
)
-- main
SELECT * FROM merged;The usability of the WITH clause aka Subquery Factoring Clause improved significantly with 11gR2. Since then it’s not necessary to reference all named queries anymore. The named queries become real transient views and this simplifies debugging a lot. – If you replace the content of line 57 with “SELECT * FROM calc_various ORDER BY oid, valid_from;” the query produces the following result:
OID VALID_FROM VALID_TO C1 C2 HAS_GAP NEW_GROUP
--- ----------- ----------- -- -- ------- ---------
1 01-JAN-2010 31-DEC-2010 A B1 0 0
1 01-JAN-2011 31-MAR-2011 A B2 0 0
1 01-JUN-2011 31-JAN-2012 A B2 1 0
1 01-APR-2012 31-DEC-9999 A B4 1 0
2 01-JAN-2010 31-JUL-2012 B B1 0 0
2 01-AUG-2012 31-DEC-9999 B B2 0 0
4 01-JAN-2010 30-SEP-2011 D D1 0 0
4 01-OCT-2011 30-SEP-2012 D2 0 1
4 01-OCT-2012 31-DEC-9999 D D3 0 1You see that the value 1 for HAS_GAP indicates that the record is not “connected” with the previous record. Additionally, the value 1 for the column NEW_GROUP indicates that the records must not be merged even if they are connected.
To simplify the calculation of NEW_GROUP for multiple group by columns (used in the named query “merged”) build a concatenated string of all relevant columns to deal with a single column similar to column C1 in this example.
HAS_GAP and NEW_GROUP are used in the subsequent named query calc_group which produces the following result:
OID VALID_FROM VALID_TO C1 C2 GROUP_NO
--- ----------- ----------- -- -- --------
1 01-JAN-2010 31-DEC-2010 A B1 0
1 01-JAN-2011 31-MAR-2011 A B2 0
1 01-JUN-2011 31-JAN-2012 A B2 1
1 01-APR-2012 31-DEC-9999 A B4 2
2 01-JAN-2010 31-JUL-2012 B B1 0
2 01-AUG-2012 31-DEC-9999 B B2 0
4 01-JAN-2010 30-SEP-2011 D D1 0
4 01-OCT-2011 30-SEP-2012 D2 1
4 01-OCT-2012 31-DEC-9999 D D3 2The GROUP_NO is calculated per OID. It’s technically a running total of HAS_GAP + NEW_GROUP. All intervals with the same GROUP_NO are mergeable. E.g. record 2, 3 and 4 have a different GROUP_NO which ensures that every single gap is honored for OID 1.
Scenario B – With Overlapping intervals
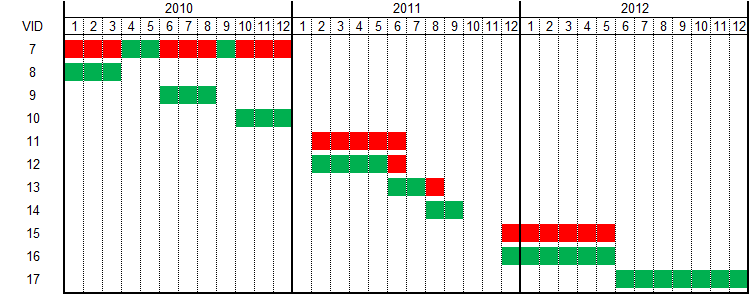
The reality is that we have sometimes to deal with inconsistent data. E.g. duplicate data intervals, overlapping data intervals or even negative data intervals (valid_to < valid_from). I’ve created an example table t2 which is in fact a copy of t1 but includes an additional messy OID 3 with the following data:
SQL> SELECT * FROM t2 WHERE oid >= 3 ORDER BY vid;
VID OID VALID_FROM VALID_TO C1 C2
---------- ---------- ----------- ----------- ---------- ----------
7 3 01-JAN-2010 31-DEC-2010 C B1
8 3 01-JAN-2010 31-MAR-2010 C B2
9 3 01-JUN-2010 31-AUG-2010 C B3
10 3 01-OCT-2010 31-DEC-2010 C B4
11 3 01-FEB-2011 30-JUN-2011 C B5
12 3 01-FEB-2011 30-JUN-2011 C B6
13 3 01-JUN-2011 31-AUG-2011 C B7
14 3 31-AUG-2011 30-SEP-2011 C B8
15 3 01-DEC-2011 31-MAY-2012 C B9
16 3 01-DEC-2011 31-MAY-2012 C B9
17 3 01-JUN-2012 31-DEC-2012 C B10The following figure visualizes the intervals of OID 3. The green patterns are expected to be used and the red patterns are expected to be ignored. The rationale is that the VID (version ID) is typically based on an Oracle Sequence and therefore it’s assumed that higher VIDs are newer and therefore more adequate. In real cases, you may have additional information such as created_at or modified_on timestamps which helps you identify the record to be used in conflicting situations. Since data is considered inconsistent in this scenario the cleansing strategy might be very different in real cases. However, cleansing is always the first step and in this example, the highest VID has the highest priority in case of conflicts.

In cleansing step 1 we gather all potential starting intervals. We do not need all these intervals, but since we will merge intervals in the last processing step, we do not have to care about some unnecessary intervals right now.
SQL> WITH
2 o AS (
3 -- object identifier and their valid_from values
4 SELECT oid, valid_from FROM t2
5 UNION
6 SELECT oid, valid_to + 1 FROM t2
7 WHERE valid_to != DATE '9999-12-31'
8 )
9 -- main
10 SELECT * FROM o WHERE oid = 3;
OID VALID_FROM
---------- -----------
3 01-JAN-2010
3 01-APR-2010
3 01-JUN-2010
3 01-SEP-2010
3 01-OCT-2010
3 01-JAN-2011
3 01-FEB-2011
3 01-JUN-2011
3 01-JUL-2011
3 31-AUG-2011
3 01-SEP-2011
3 01-OCT-2011
3 01-DEC-2011
3 01-JUN-2012
3 01-JAN-2013
15 rows selected.In cleansing step 2 we calculate the relevant VID for every previous result. Additionally, we may inexpensively calculate if an interval is a gap.
SQL> WITH
2 o AS (
3 -- object identifier and their valid_from values
4 SELECT oid, valid_from FROM t2
5 UNION
6 SELECT oid, valid_to + 1 FROM t2
7 WHERE valid_to != DATE '9999-12-31'
8 ),
9 v AS (
10 -- relevant version identifier per valid_from
11 -- produces column is_gap
12 SELECT o.oid,
13 MAX(vid) AS vid,
14 o.valid_from,
15 NVL2(MAX(vid), 0, 1) AS is_gap
16 FROM o
17 LEFT JOIN t2
18 ON t2.oid = o.oid
19 AND o.valid_from BETWEEN t2.valid_from AND t2.valid_to
20 GROUP BY o.oid, o.valid_from
21 )
22 -- main
23 SELECT * FROM v WHERE oid = 3 ORDER BY valid_from;
OID VID VALID_FROM IS_GAP
---------- ---------- ----------- ----------
3 8 01-JAN-2010 0
3 7 01-APR-2010 0
3 9 01-JUN-2010 0
3 7 01-SEP-2010 0
3 10 01-OCT-2010 0
3 01-JAN-2011 1
3 12 01-FEB-2011 0
3 13 01-JUN-2011 0
3 13 01-JUL-2011 0
3 14 31-AUG-2011 0
3 14 01-SEP-2011 0
3 01-OCT-2011 1
3 16 01-DEC-2011 0
3 17 01-JUN-2012 0
3 01-JAN-2013 1
15 rows selected.In cleansing step 3 we extend the previous result by the missing columns from table t2 and calculate the NEW_GROUP column with the same logic as in scenario A.
SQL> WITH
2 o AS (
3 -- object identifier and their valid_from values
4 SELECT oid, valid_from FROM t2
5 UNION
6 SELECT oid, valid_to + 1 FROM t2
7 WHERE valid_to != DATE '9999-12-31'
8 ),
9 v AS (
10 -- relevant version identifier per valid_from
11 -- produces column is_gap
12 SELECT o.oid,
13 MAX(vid) AS vid,
14 o.valid_from,
15 NVL2(MAX(vid), 0, 1) AS is_gap
16 FROM o
17 LEFT JOIN t2
18 ON t2.oid = o.oid
19 AND o.valid_from BETWEEN t2.valid_from AND t2.valid_to
20 GROUP BY o.oid, o.valid_from
21 ),
22 combined AS (
23 -- combines previous intermediate result v with t2
24 -- produces the valid_to and new_group columns
25 SELECT t2.vid,
26 v.oid,
27 v.valid_from,
28 LEAD(v.valid_from - 1, 1, DATE '9999-12-31') OVER (
29 PARTITION BY v.oid ORDER BY v.valid_from
30 ) AS valid_to,
31 t2.c1,
32 t2.c2,
33 v.is_gap,
34 CASE
35 WHEN LAG(t2.c1, 1, t2.c1) OVER(
36 PARTITION BY t2.oid ORDER BY t2.valid_from
37 ) = c1 THEN
38 0
39 ELSE
40 1
41 END AS new_group
42 FROM v
43 LEFT JOIN t2
44 ON t2.oid = v.oid
45 AND t2.vid = v.vid
46 AND v.valid_from BETWEEN t2.valid_from AND t2.valid_to
47 )
48 -- main
49 SELECT * FROM combined WHERE oid = 3 ORDER BY valid_from;
VID OID VALID_FROM VALID_TO C1 C2 IS_GAP NEW_GROUP
--- --- ----------- ----------- -- --- ------ ---------
8 3 01-JAN-2010 31-MAR-2010 C B2 0 0
7 3 01-APR-2010 31-MAY-2010 C B1 0 0
9 3 01-JUN-2010 31-AUG-2010 C B3 0 0
7 3 01-SEP-2010 30-SEP-2010 C B1 0 0
10 3 01-OCT-2010 31-DEC-2010 C B4 0 0
3 01-JAN-2011 31-JAN-2011 1 1
12 3 01-FEB-2011 31-MAY-2011 C B6 0 0
13 3 01-JUN-2011 30-JUN-2011 C B7 0 0
13 3 01-JUL-2011 30-AUG-2011 C B7 0 0
14 3 31-AUG-2011 31-AUG-2011 C B8 0 0
14 3 01-SEP-2011 30-SEP-2011 C B8 0 0
3 01-OCT-2011 30-NOV-2011 1 1
16 3 01-DEC-2011 31-MAY-2012 C B9 0 0
17 3 01-JUN-2012 31-DEC-2012 C B10 0 0
3 01-JAN-2013 31-DEC-9999 1 1
15 rows selected.Now we have cleansed the data and are ready for the final steps “calc_group” and “merge” which are very similar to scenario A. The relevant difference is the highlighted line 70 which filters non-gap records. Here is the complete statement and the query result:
WITH
o AS (
-- object identifier and their valid_from values
SELECT oid, valid_from FROM t2
UNION
SELECT oid, valid_to + 1 FROM t2
WHERE valid_to != DATE '9999-12-31'
),
v AS (
-- relevant version identifier per valid_from
-- produces column is_gap
SELECT o.oid,
MAX(vid) AS vid,
o.valid_from,
NVL2(MAX(vid), 0, 1) AS is_gap
FROM o
LEFT JOIN t2
ON t2.oid = o.oid
AND o.valid_from BETWEEN t2.valid_from AND t2.valid_to
GROUP BY o.oid, o.valid_from
),
combined AS (
-- combines previous intermediate result v with t2
-- produces the valid_to and new_group columns
SELECT t2.vid,
v.oid,
v.valid_from,
LEAD(v.valid_from - 1, 1, DATE '9999-12-31') OVER (
PARTITION BY v.oid ORDER BY v.valid_from
) AS valid_to,
t2.c1,
t2.c2,
v.is_gap,
CASE
WHEN LAG(t2.c1, 1, t2.c1) OVER(
PARTITION BY t2.oid ORDER BY t2.valid_from
) = c1 THEN
0
ELSE
1
END AS new_group
FROM v
LEFT JOIN t2
ON t2.oid = v.oid
AND t2.vid = v.vid
AND v.valid_from BETWEEN t2.valid_from AND t2.valid_to
),
calc_group AS (
-- produces column group_no, records with the same group_no
-- are mergeable, group_no is calculated per oid
SELECT oid,
valid_from,
valid_to,
c1,
c2,
is_gap,
SUM(is_gap + new_group) OVER(
PARTITION BY oid ORDER BY oid, valid_from
) AS group_no
FROM combined
),
merged AS (
-- produces the final merged result
-- grouping by group_no ensures that gaps are honored
SELECT oid,
MIN(valid_from) AS valid_from,
MAX(valid_to) AS valid_to,
c1
FROM calc_group
WHERE is_gap = 0
GROUP BY OID, c1, group_no
ORDER BY OID, valid_from
)
-- main
SELECT * FROM merged; OID VALID_FROM VALID_TO C1
---------- ----------- ----------- ----------
1 01-JAN-2010 31-MAR-2011 A
1 01-JUN-2011 31-JAN-2012 A
1 01-APR-2012 31-DEC-9999 A
2 01-JAN-2010 31-DEC-9999 B
3 01-JAN-2010 31-DEC-2010 C
3 01-FEB-2011 30-SEP-2011 C
3 01-DEC-2011 31-DEC-2012 C
4 01-JAN-2010 30-SEP-2011 D
4 01-OCT-2011 30-SEP-2012
4 01-OCT-2012 31-DEC-9999 DIf you change line 70 to “WHERE is_gap = 1” you’ll get all gap records, just a way to query non-existing intervals.
OID VALID_FROM VALID_TO C1
---------- ----------- ----------- ----------
1 01-APR-2011 31-MAY-2011
1 01-FEB-2012 31-MAR-2012
3 01-JAN-2011 31-JAN-2011
3 01-OCT-2011 30-NOV-2011
3 01-JAN-2013 31-DEC-9999Conclusion
Merging temporal intervals is challenging, especially if the history has gaps and the data is inconsistent as in scenario B. However, the SQL engine is a powerful tool to clean up data and merge the temporal intervals efficiently in a single SQL statement.
1 Comment
[…] Merging Temporal Intervals with Gaps → […]