

Introduction
Everything Changes. Our Trivadis SQL & PL/SQL Coding Guidelines are no exceptions. We plan to change rule #1 of our coding styles. From “Keywords are written uppercase, names are written in lowercase.” to “Keywords and names are written in lowercase.“. We have 103 Markdown files and most of them contain several SQL code blocks complying to our current (old) rule #1. Should we change these files manually? Nah, this is boring and error-prone. It’s a perfect case to automate it and to show how you can format SQL code blocks in Markdown with SQLcl.
Tools
For this task, we use SQLcl 20.2.0. If you work with Oracle databases, you have most likely already installed it.
SQLcl is basically SQL*Plus on steroids. One of the most underestimated features of SQLcl is the ability to execute JavaScript and provide them as custom SQLcl commands (read Erik van Roon‘s excellent blog post to learn more about it). We use the custom command tvdformat. To install it, save format.js locally in a folder of your choice. Then start SQLcl (no connection required), go to the folder where you’ve saved format.js and run script format.js -r. This will register the command tvdformat. You get the usage help, when you enter the command without arguments.
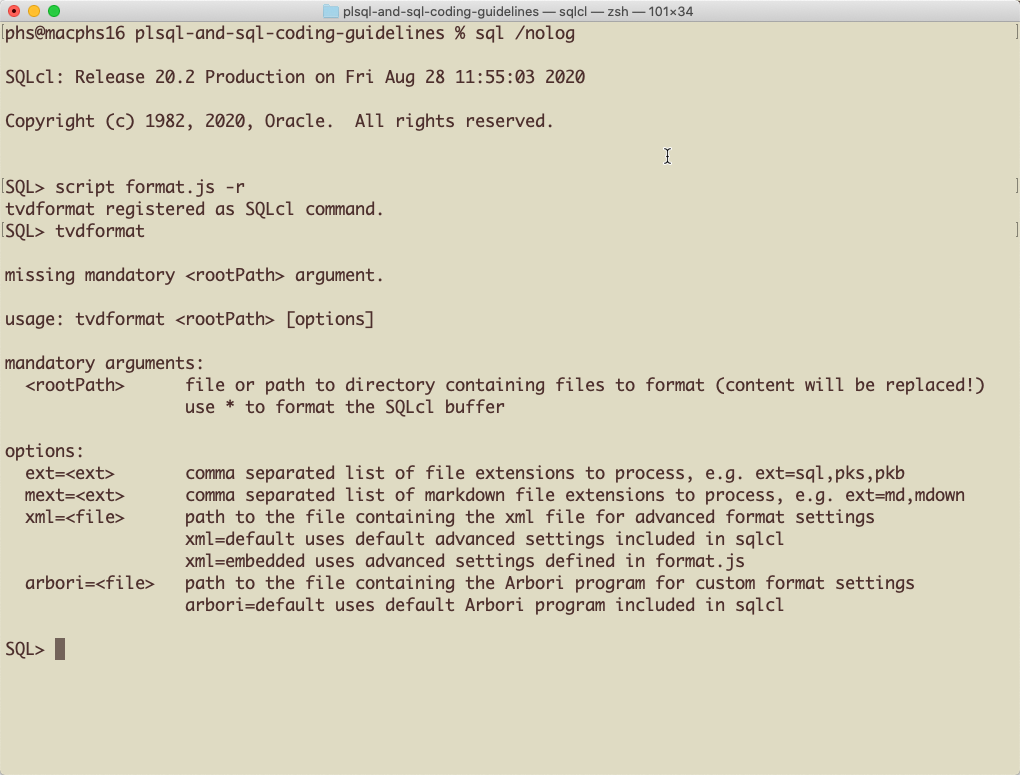
Formatting a Single Markdown File
Let’s create a simple Markdown file to see how the formatter behaves.
## SQL to be formated
``` sql
SELECT * FROM EMP JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
```
## SQL to be ignored
```
SELECT * FROM EMP JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
```
## JavaScript to be ignored
``` js
var foo = function (bar) {
return bar++;
};
```Save the content in a file named example.md. And then run tvdformat example.md. This will format this file with default settings. Default means with the embedded advanced settings (xml) and the default custom settings (arbori).
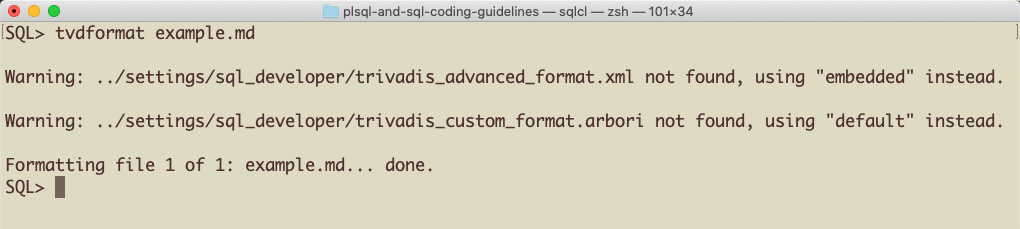
The result should look like this:
## SQL to be formated
``` sql
SELECT *
FROM EMP
JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;
```
## SQL to be ignored
```
SELECT * FROM EMP JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
```
## JavaScript to be ignored
``` js
var foo = function (bar) {
return bar++;
};
```As you see only the first SQL statement is formatted. The other code blocks are left as is. Only code blocks with sql syntax highlighting are formatted.
The indentation of line 7 is wrong. It’s an issue of the default Arbori program. It’s addressed in trivadis_custom_format.arbori. However, we do not want to format the code blocks anyway. We just want to change the keywords and identifiers to lowercase.
Changing Keywords and Identifiers to Lowercase
You can export the advanced format settings in SQL Developer. When you look at the options in the resulting XML file, the first option is adjustCaseOnly. This option cannot be set in the Advanced Format preferences. It’s set to false by default. When changed to true the formatter still executes some part of the Arbori program, but basically skips all actions that deal with whitespace before a node. Knowing that we can create the following options.xml file:
<options>
<adjustCaseOnly>true</adjustCaseOnly>
<idCase>oracle.dbtools.app.Format.Case.lower</idCase>
<kwCase>oracle.dbtools.app.Format.Case.lower</kwCase>
</options>Let’s reset the content of example.md to the unformatted one. And then run tvdformat example.md xml=options.xml.

Now, the result should look like this:
## SQL to be formated
``` sql
select * from emp join dept on emp.deptno = dept.deptno;
```
## SQL to be ignored
```
SELECT * FROM EMP JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
```
## JavaScript to be ignored
``` js
var foo = function (bar) {
return bar++;
};
```
As before, only the first code block changed. In this case, everything is in lowercase. However, the processing is more complicated behind the scenes. For example: comments, strings, and quoted identifiers are left untouched. So, it’s more than just a simple .toLowerCase() call and for sure worth using Oracle’s formatter for this task.
Is it Safe to Change the Case in PL/SQL & SQL?
PL/SQL & SQL are case-insensitive languages. So you might be tempted to answer this question with “Yes”. But it is not that easy. For keywords, it’s 100% true. However, this is not true for identifiers. Roger Troller was the first who showed me examples of unquoted, case-sensitive identifiers in SQL. One is documented here. For example, if you use JSON columns the items in the JSON document are case-sensitive. Changing the case will break the code. That’s bad. This is also the reason, why we do not change the case of identifiers in our formatter configuration.
Therefore, be careful, if you change the case of identifiers. This might break your code. Depending on your test coverage you might detect this problem very late, because the program might still compile, but not produce the expected results anymore (as in the mentioned example).
Bulk Processing
In our case, we know that we do not have JSON-based code snippets in our Markdown files. Therefore it is safe to change the case of identifiers in all files.
To process all files in the docs directory including all subdirectories I run tvdformat docs xml=options.xml arbori=default. I pass the arbori option only to avoid the warning message.
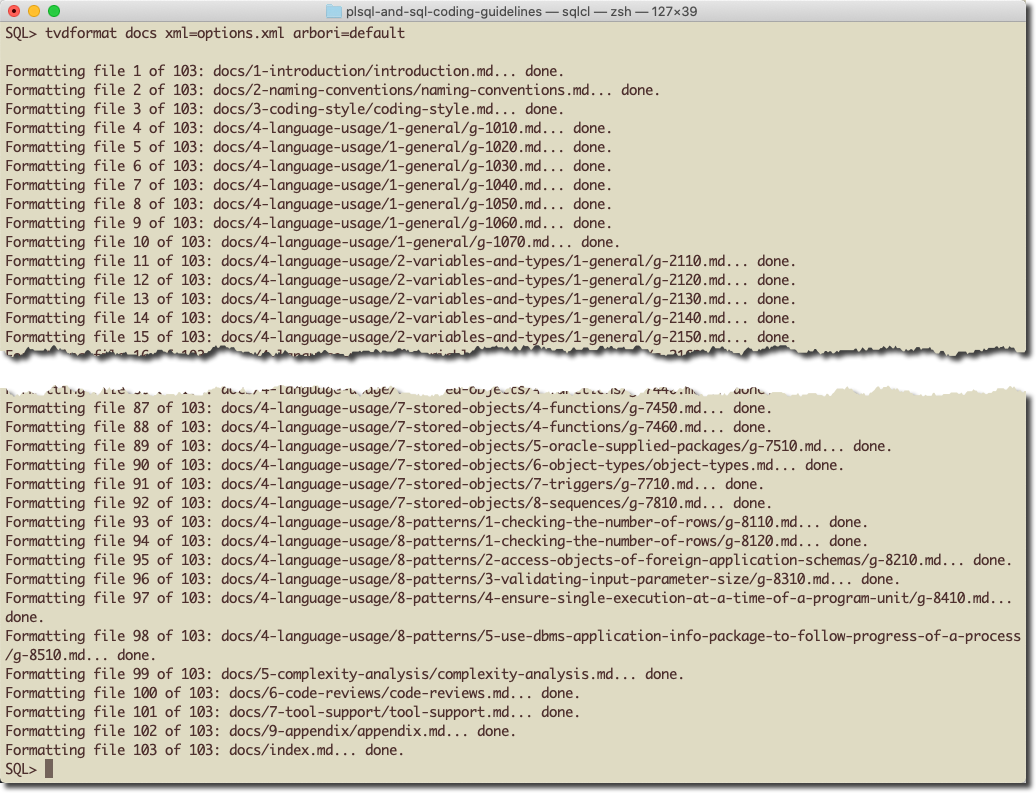
In this case, the code is based on a Git repository. Therefore I can browse through the changes before committing them. Here’s an excerpt of the g-1050.md file.
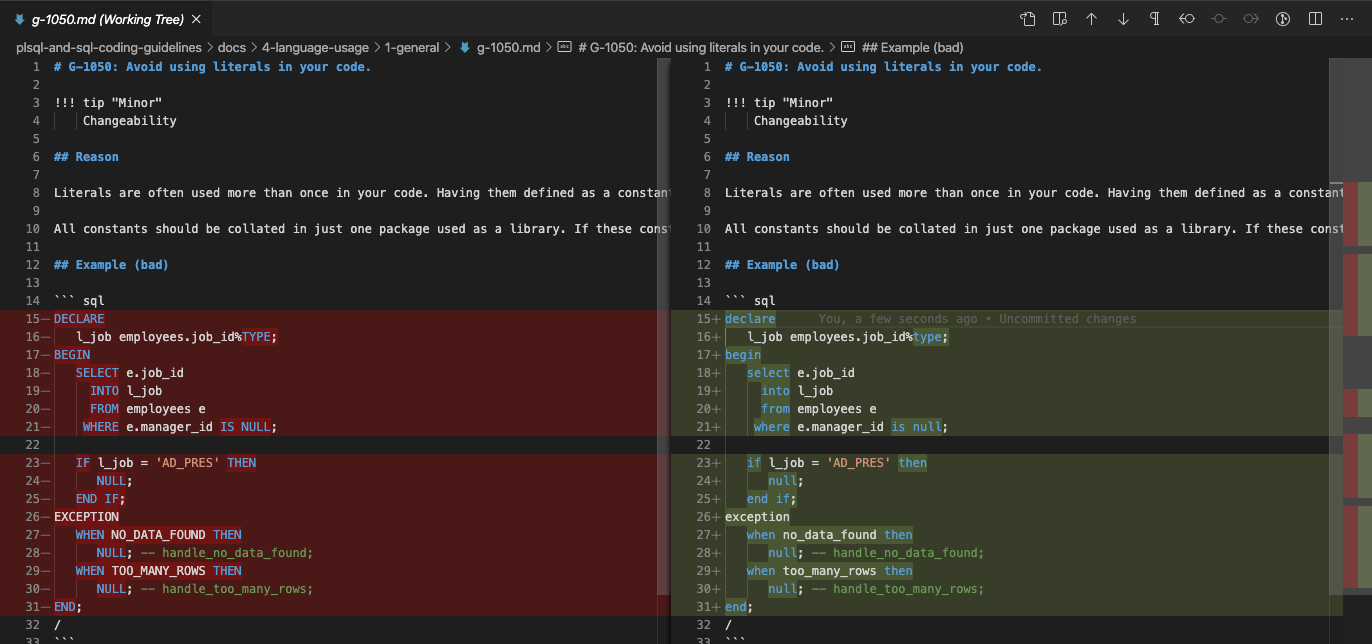
You see that the original whitespace is preserved. Only keywords and identifiers are changed to lowercase. The string ‘AD_PERS’ is still in uppercase. This looks good. Ready to be checked in.
Recommendations
The current formatter settings are probably not good enough for all code. There are for sure some cases where the original code base is formatted so badly, that an imperfect formatting configuration leads to a huge improvement. But generally, this is not good enough. You can use the formatter when writing code. That includes changing existing code when the current formatting style makes it difficult to read. You can always select a portion of code (a subquery, a function, etc.), format it and then change the things you don’t like. It’s easy to undo the changes in the IDE. This is also possible if you apply the formatter for a large number of files, especially if you use a version control system such as Git. It is simple to undo everything. However, when you change hundreds of files you will easily overlook some uglified code.
For bulk processing, changing the case of keywords is safe. Changing the case of identifiers is possible. But be careful, if you are using case-sensitive SQL, this will break your code.
Whatever you do, make sure you keep the version before applying the formatter. And do not forget to test and review the result.