

Introduction
In this blog post, I explained how the formatter in SQL Developer works and outlined how you can change the formatter result using Arbori and JavaScript. In this post, I explain what exactly the provided formatter callback functions do. For that, I use simple examples. I produced all results with a patched version of SQL Developer 20.2. However, I expect that the results for versions 20.2, 19.4 and 19.2 will be the same.
Minimal Arbori Program
Before looking at the callback function, I’d like to reduce the Arbori program to the minimum. Why? Because this visualises the default behaviour of the formatter. Furthermore, it will simplify the subsequent examples.
One could think about removing the entire Arbori program. But that won’t work. An empty Arbori program is an invalid Arbori program and SQL Developer will reset it to the default.
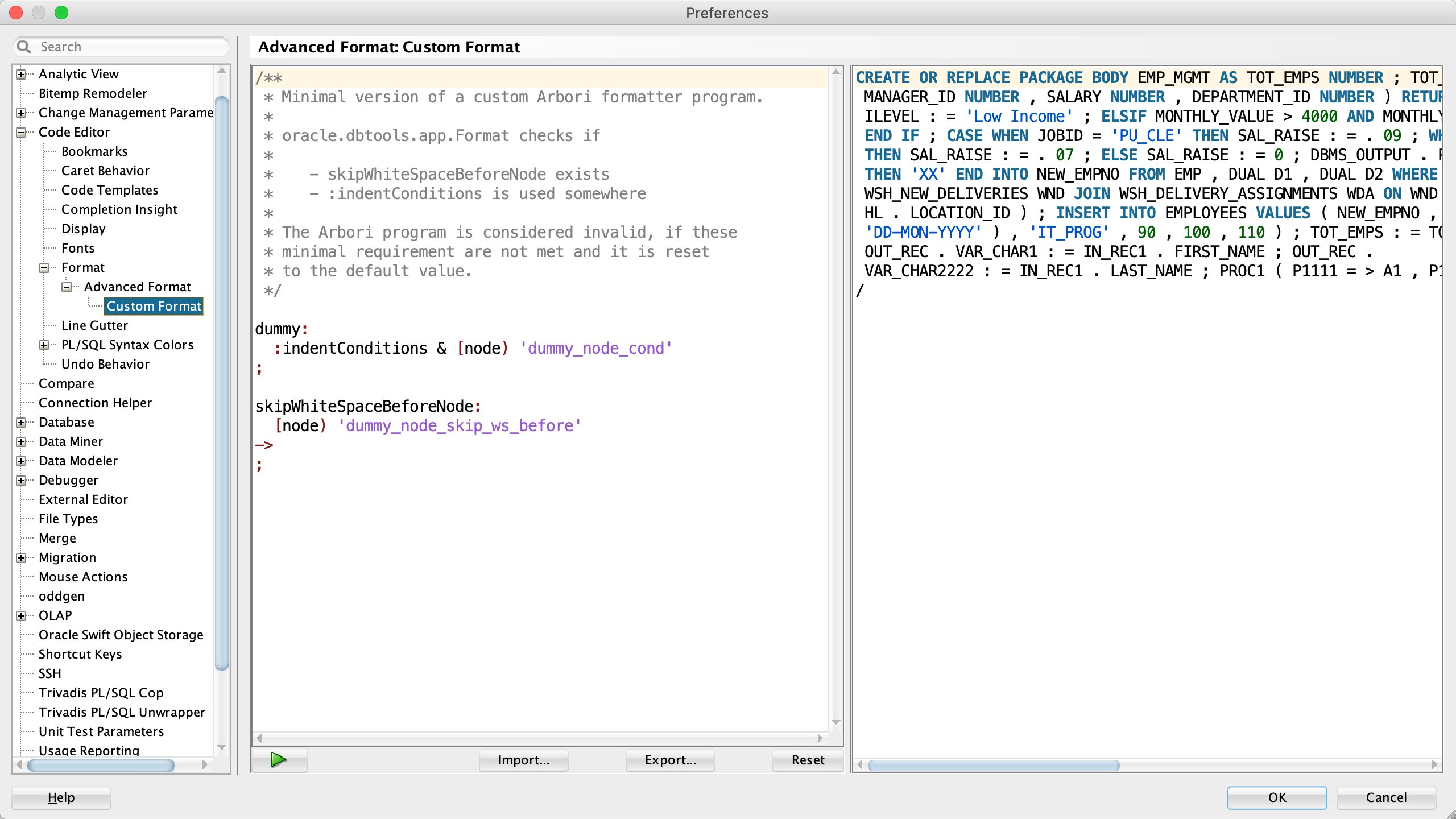
A minimal Arbori program looks as follows, the comment section explains the required parts.
/**
* Minimal version of a custom Arbori formatter program.
*
* oracle.dbtools.app.Format checks if
*
* - skipWhiteSpaceBeforeNode exists
* - :indentConditions is used somewhere
*
* The Arbori program is considered invalid, if these
* minimal requirement are not met and it is reset
* to the default value.
*/
dummy:
:indentConditions & [node) 'dummy_node_cond'
;
skipWhiteSpaceBeforeNode:
[node) 'dummy_node_skip_ws_before'
->
;I use default values for all other formatter settings as the following three screenshots show.
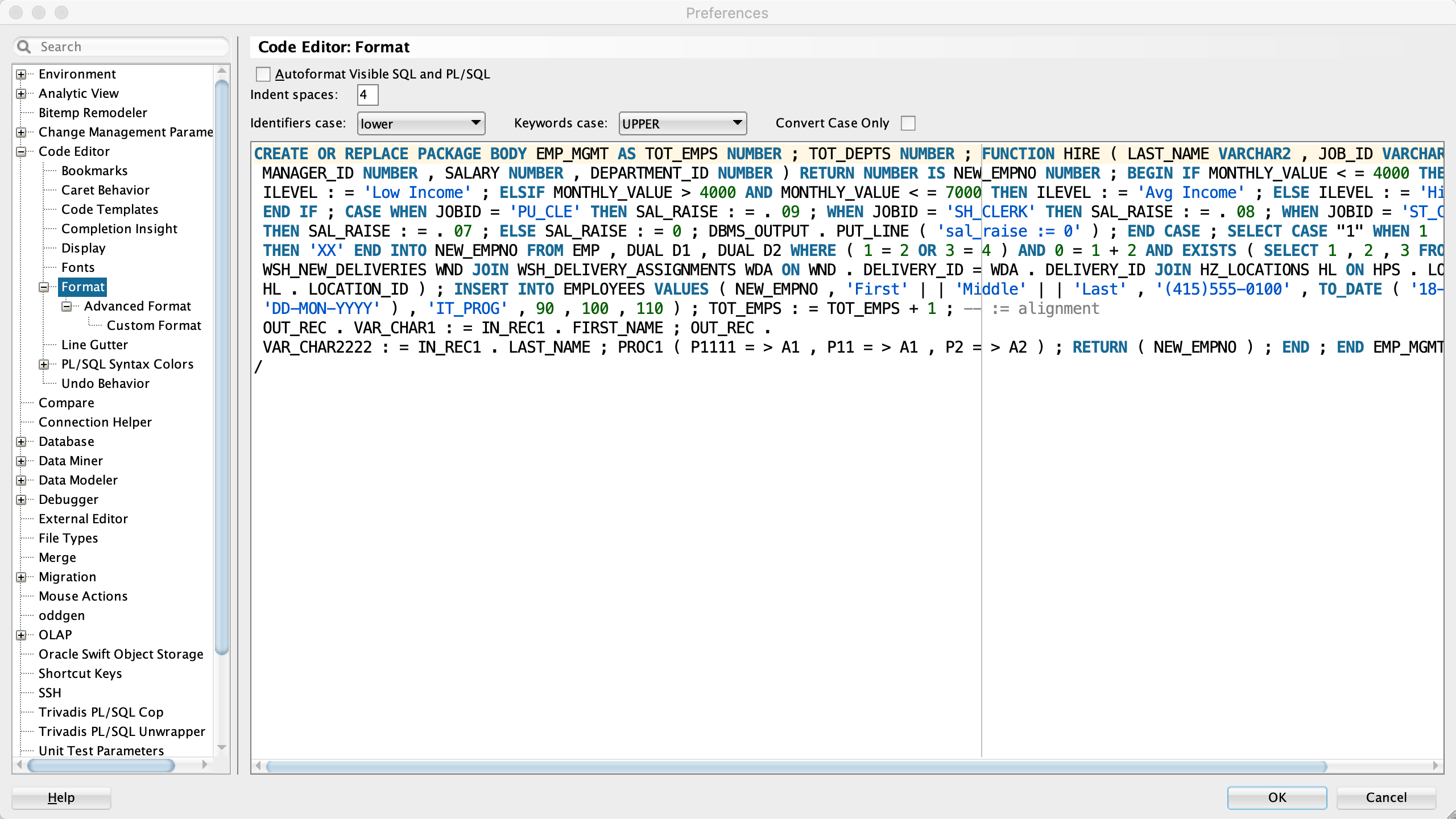
You can see that tokens are separated by a space. A line break is added after reaching the line size limit. Keywords are changed to upper case. However, all identifiers are treated as keywords. No identifiers are changed to lowercase as configured. Besides the “1-line long comments” setting no other configuration has an effect with this minimal Arbori program. In other words, the Arbori program is involved in the application of most formatter configuration settings.
Just to be clear. This Arbori program does nothing. :indentConditions is technically used in the dummyquery, but the query does not produce a result. Even if it would, it is not used anywhere. And the query skipWhiteSpaceBeforeNode looks for a non-existing node type. So the query returns no result and therefore the callback function skipWhiteSpaceBeforeNode is not called.
Callback Functions
A formatter callback function in SQL Developer has the following Java signature:
public void callbackFunctionName (
oracle.dbtools.parser.Parsed target,
Map<String, oracle.dbtools.parser.ParseNode> tuple
) {...}target contains the parse tree. And tuple contains the nodes to process. An Arbori query can return multiple columns and multiple rows. A tuple contains the columns of a single row. Therefore, a callback function is called per Arbori query result row. But what columns are expected in tuple. I have not found a document describing that. This is one of the reasons for this blog post. Most of the callback functions expect a column named node. But not all of them.
Most of the formatter callback functions just populate an internal list of whitespace before a node. Technically it is implemented as a Map<Integer, String> and is named newLinePositions. The key (Integer) is the position of a node (lexer token) in the parse tree. The value (String) contains the whitespace before this position.
Most callback functions expect existing entries in newLinePositions. This leads to a strict execution order.
Here’s the ordered list of all callback functions. I highlighted the functions that you can call at any position in an Arbori program.
indentedNodes1indentedNodes2skipWhiteSpaceBeforeNode(any position)skipWhiteSpaceAfterNode(any position)identifiers(any position)extraBrkBeforeextraBrkAfterbrkX2rightAlignmentspaddedIdsInScopeincrementalAlignmentspairwiseAlignmentsignoreLineBreaksBeforeNodeignoreLineBreaksAfterNodedontFormatNode(any position)
I will discuss them in the next chapters based on this example:
SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF r.salary > 2.9e3 THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/SET SERVEROUTPUT ON BEGIN FOR R IN ( SELECT ENAME AS EMP_NAME , SAL AS SALARY FROM EMP WHERE DEPTNO IN ( 10 , 20 ) ) LOOP IF R . SALARY >
2 . 9 E 3 THEN DBMS_OUTPUT . PUT_LINE ( R . EMP_NAME ) ; END IF ; END LOOP ; END ;
/dontFormatNode
I start with this function because the example contains an exponential number 2.9e3. The default formatting adds spaces around all lexer tokens. The result 2 . 9 E 3 breaks the code. I’d like to fix that first, so we are not distracted by this syntax error and can concentrate on formatting code.
This function expects a node in tuple. It identifies nodes that must not be formatted. In other words, the node keeps all its whitespace. Behind the scenes, the function adds all positions to a Map<Integer> named unformattedPositions. The serializer will ignore all positions in newLinePositions if a position exists in unformattedPositions. As a result, the position of dontFormatNode in the Arbori program is irrelevant.
In this blog post I showed how you can use dontFormatNode to ignore chosen code sections with @formatter:off and @formatter:on comments.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
dummy:
:indentConditions & [node) 'dummy_node_cond'
;
skipWhiteSpaceBeforeNode:
[node) 'dummy_node_skip_ws_before'
->
;SET SERVEROUTPUT ON BEGIN FOR R IN ( SELECT ENAME AS EMP_NAME , SAL AS SALARY FROM EMP WHERE DEPTNO IN ( 10 , 20 ) ) LOOP IF R . SALARY >
2 . 9 E 3 THEN DBMS_OUTPUT . PUT_LINE ( R . EMP_NAME ) ; END IF ; END LOOP ; END ;
/On line 2 you find the query condition. The -> on line 3 calls the callback function. The name of the function musts match the query name. In this case dontFormatNode. The result shows a difference on line 2. The numeric literal 2.9e3 does not contain whitespace anymore.
indentedNodes1
This function expects an node in tuple. It’s a preparation step for indentedNodes2. Calling this function alone will not change the formatting result. It populates a Map<Integer, Integer> named posDepths. The key is the position and the value is the number of indentations. You can think of an indentation as the number of tabs, even if you use spaces for indentation.
indentedNodes2
This function expects the very same input as for indentedNodes1. It converts the number of indentations to spaces or tabs according to the formatter configuration and adds them to newLinePositions.
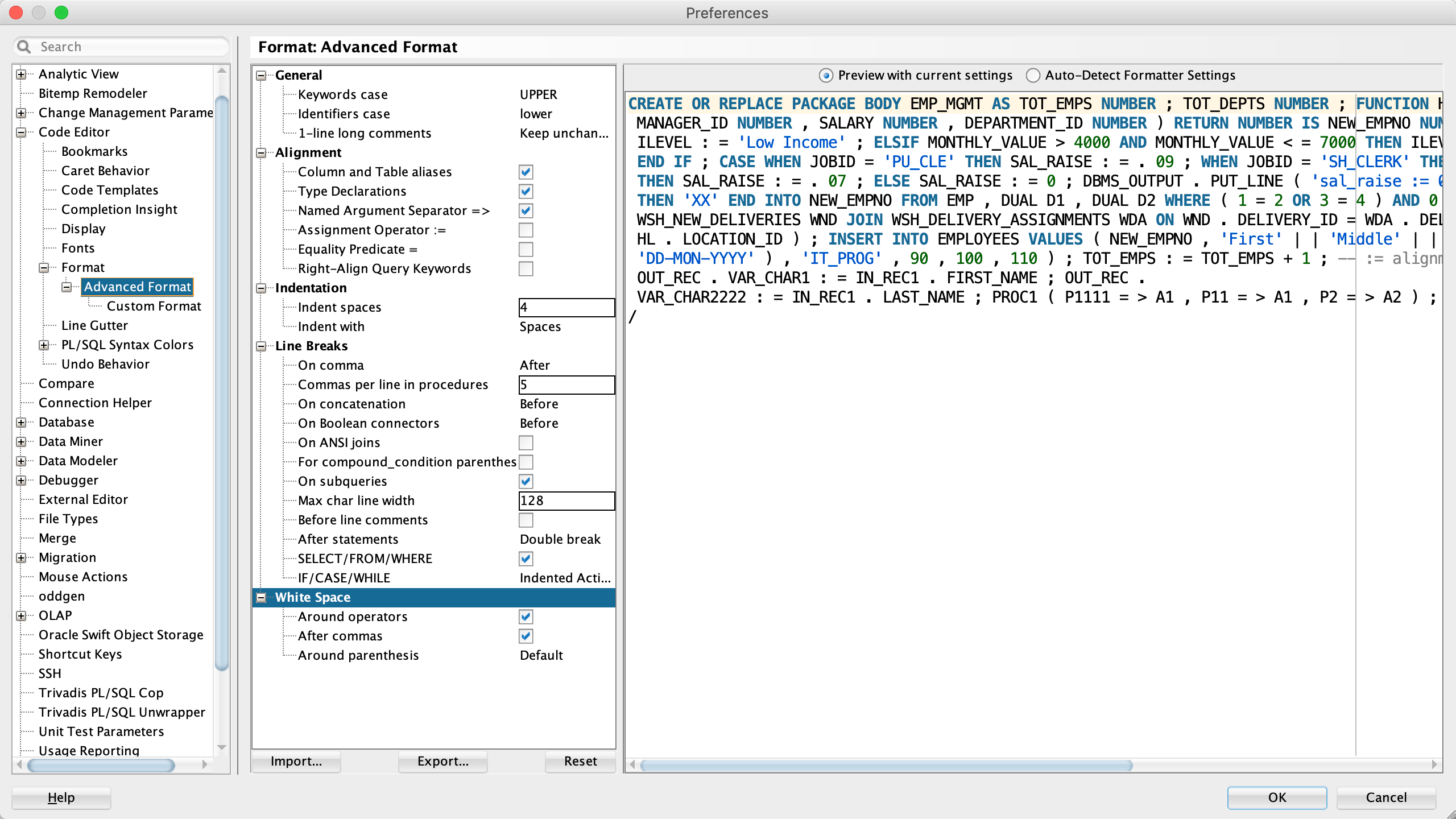
The Arbori program uses :indentConditions on line 8. This is a parameterless function returning a Boolean value. It’s part of the formatter and can be used in an Arbori query. :indentConditions returns true if the setting for “Line Breaks IF/CASE/WHILE” is set to “Indented Conditions and Actions” as in the following screenshot.

Here is the Arbori program and the formatting results. The first result is based on the default settings for “Line Breaks IF/CASE/WHILE” (Indented Actions, Inlined Conditions) and the second result is based on “Indented Conditions and Actions.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) 'dummy_node_skip_ws_before'
->
;SET SERVEROUTPUT ON BEGIN
FOR R IN ( SELECT ENAME AS EMP_NAME , SAL AS SALARY FROM EMP WHERE DEPTNO IN ( 10 , 20 ) ) LOOP
IF R . SALARY > 2.9e3 THEN
DBMS_OUTPUT . PUT_LINE ( R . EMP_NAME ) ;
END IF ;
END LOOP ;
END ;
/SET SERVEROUTPUT ON BEGIN
FOR R IN ( SELECT ENAME AS EMP_NAME , SAL AS SALARY FROM EMP WHERE DEPTNO IN ( 10 , 20 ) ) LOOP
IF
R . SALARY > 2.9e3
THEN
DBMS_OUTPUT . PUT_LINE ( R . EMP_NAME ) ;
END IF ;
END LOOP ;
END ;
/The query condition is defined on lines 6 to 9 and is used on lines 11 and 15. This change has a huge impact on the formatting result. Both results look quite good.
You also see that the Arbori program is responsible for dealing with different formatter settings. To simplify the Arbori program I will ignore all other formatter settings. All further formatting results are based on :indentConditions.
skipWhiteSpaceBeforeNode
This function expects an node in tuple. It adds the starting position of the node to a Map<Integer> named skipWSPositions. The serializer will use this map and change the default behaviour accordingly. This means it will emit no whitespace instead of a single whitespace at this node position. As a result, the position of skipWhiteSpaceBeforeNode in the Arbori program is irrelevant.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;SET SERVEROUTPUT ON BEGIN
FOR R IN ( SELECT ENAME AS EMP_NAME, SAL AS SALARY FROM EMP WHERE DEPTNO IN ( 10, 20)) LOOP
IF
R. SALARY > 2.9e3
THEN
DBMS_OUTPUT. PUT_LINE ( R. EMP_NAME);
END IF;
END LOOP;
END;
/The formatter removed the space before ;, ,, ) and . on lines 2, 4, 6, 7 and 8.
skipWhiteSpaceAfterNode
This function expects an node in tuple. It is similar to skipWhiteSpaceBeforeNode. The only difference is that it adds the end position of a node to d skipWSPositions.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;SET SERVEROUTPUT ON BEGIN
FOR R IN (SELECT ENAME AS EMP_NAME, SAL AS SALARY FROM EMP WHERE DEPTNO IN (10, 20)) LOOP
IF
R.SALARY > 2.9e3
THEN
DBMS_OUTPUT.PUT_LINE (R.EMP_NAME);
END IF;
END LOOP;
END;
/The formatter removed the space after (, and . on lineS 2, 4 and 6.
identifiers
This function expects an identifier in tuple. It populates a Map<String, String> named caseIds. The key is an interval representation of a node (containing to and from position). The value contains the identifier according to the formatter settings. The serializer will use this map to emit the identifiers in the configured case. newLinePositions is not used. As a result, the position of identifiers in the Arbori program is irrelevant.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;SET SERVEROUTPUT ON BEGIN
FOR r IN (SELECT ename AS emp_name, sal AS salary FROM emp WHERE deptno IN (10, 20)) LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/You see that the identifiers r, ename, emp_name, sal, salary, emp, dbms_output and put_line are in lowercase.
extraBrkBefore
This function expects an node in tuple. It extracts the whitespace at the starting position newLinePositions and adds a leading newline.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name, sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added a newline before BEGIN on line 2, before FROM on line 4, before WHERE on line 5 and before LOOP on line 6.
extraBrkAfter
This function expects an node in tuple. It is similar to extraBrkBefore. The only difference is that it adds the end position of a node to newLinePositions.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added a newline after , on line 3.
brkX2
This function expects an node in tuple. A node identifies a significant statement.
Depending on the setting for “Line Breaks After statement” one or two newlines are added to newLinePositions. For “Preserve Original” the original newline characters will be extracted from the source during serialization. “Preserve Original” means that it will also preserve missing newlines. As a result, the formatting result may differ based on the input.
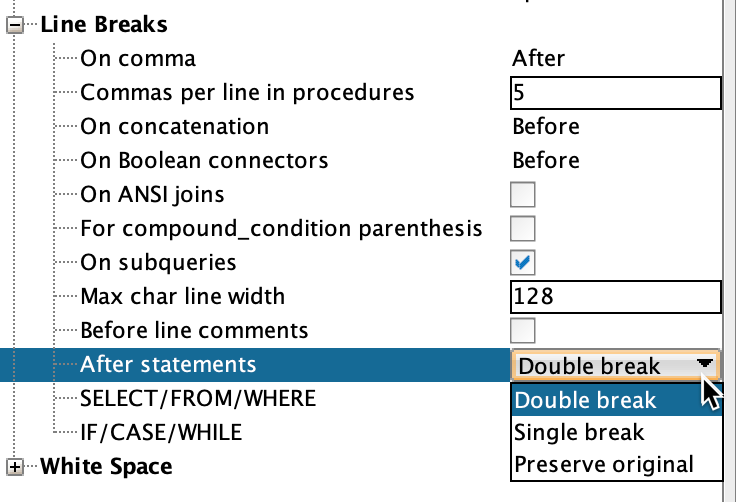
“Double break” is the default.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatting result has an additional empty line on line 2.
rightAlignments
This function expects an node in tuple. It calculates the length in characters of the passed node. If it is less than 6 (the length of the SELECT keyword), then the missing spaces are added to newLinePositions.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added two spaces before the FROM on line 6 and one space before the WHERE on line 7. However, the query block is not yet right-aligned. This will happen in incrementalAlignments.
paddedIdsInScope
This function expects a scope, predecessor and follower in tuple. It populates the following fields:
maxLengthInScopeof typeMap<String, Integer>, where the key is an interval representation of ascope(containing to and from position) and the value of the calculated max lengthid2scopeof typeMap<Integer, String>, where the key is the start position of afollowernode and the value an interval representation of ascope(containing to and from position)id2intervalof typeMap<Integer, Integer>, where the key is the start position of afollowernode and the value of the start position of apredecessornodeid2adjustmentsof typeMap<Integer, Integer>, where the key is the start position of afollowernode and the value is the indentation
The newLinePositions field is read but not written. As a result, the position of paddedIdsInScope in the Arbori program is important.
The serializer adds the necessary number of spaces between the predecessor and follower nodes to left-align followers within the scope.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;
paddedIdsInScope:
[id) expr & [id^) select_term & [id+1) as_alias & [scope) select_clause
& scope < id & predecessor = id & follower = id+1
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added one space before the AS on line 4 and two spaces before the AS on line 5. However, the result looks wrong because ename and sal are not yet left-aligned. This will happen in pairwiseAlignments.
incrementalAlignments
This function expects an node in tuple. It adds spaces to all children with a content in newLinePositions to left-align them with the start position in node.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;
paddedIdsInScope:
[id) expr & [id^) select_term & [id+1) as_alias & [scope) select_clause
& scope < id & predecessor = id & follower = id+1
->
;
incrementalAlignments:
[node) subquery
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added ten spaces at the beginning of line 5, 6 and 7. As a result SELECT, sal, FROM and WHERE are now left-aligned. Please note that the algorithm considers the spaces added in rightAlignments.
pairwiseAlignments
This function expects a node and a predecessor in tuple. It left-aligns the node with its predecessor by adding spaces to newLinePositions for the start position of node.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;
paddedIdsInScope:
[id) expr & [id^) select_term & [id+1) as_alias & [scope) select_clause
& scope < id & predecessor = id & follower = id+1
->
;
incrementalAlignments:
[node) subquery
->
;
pairwiseAlignments:
[predecessor) select_list & [node) select_term & [node-1) ',' & predecessor=node-1-1
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF
r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatter added seven spaces at the beginning of line 5. Now all select terms are left-aligned.
ignoreLineBreaksBeforeNode
This function expects an node in tuple. It removes the entry in newLinePositions for the start position of the node. As a result, the serializer will emit a space before this node.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;
paddedIdsInScope:
[id) expr & [id^) select_term & [id+1) as_alias & [scope) select_clause
& scope < id & predecessor = id & follower = id+1
->
;
incrementalAlignments:
[node) subquery
->
;
pairwiseAlignments:
[predecessor) select_list & [node) select_term & [node-1) ',' & predecessor=node-1-1
->
;
ignoreLineBreaksBeforeNode:
[node) pls_expr & [node-1) 'IF' /* override breaks in indentedNodes */
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF r.salary > 2.9e3
THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/The formatting result does not contain a newline after the IF on line 9.
ignoreLineBreaksAfterNode
This function expects an node in tuple. It is similar to ignoreLineBreaksBeforeNode. The only difference is that it removes the end position of a node from newLinePositions.
Here is the Arbori program and its formatting result.
dontFormatNode:
[node) numeric_literal
->
;
indentedNodes:
[node) seq_of_stmts
| :indentConditions & [node) pls_expr & [node-1) 'IF'
;
indentedNodes1: indentedNodes
->
;
indentedNodes2: indentedNodes
->
;
skipWhiteSpaceBeforeNode:
[node) ';'
| [node) ','
| [node) ')'
| [node) '.'
->
;
skipWhiteSpaceAfterNode:
[node) '('
| [node) '.'
->
;
identifiers:
[identifier) identifier
->
;
extraBrkBefore:
[node) sql_statement
| [node) from_clause
| [node) where_clause
| [node) 'LOOP' & [node-1) iteration_scheme
->
;
extraBrkAfter:
[node) ',' & [node+1) select_term
->
;
brkX2:
[node) sql_statement
->
;
rightAlignments:
[node) 'FROM'
| [node) 'WHERE'
->
;
paddedIdsInScope:
[id) expr & [id^) select_term & [id+1) as_alias & [scope) select_clause
& scope < id & predecessor = id & follower = id+1
->
;
incrementalAlignments:
[node) subquery
->
;
pairwiseAlignments:
[predecessor) select_list & [node) select_term & [node-1) ',' & predecessor=node-1-1
->
;
ignoreLineBreaksBeforeNode:
[node) pls_expr & [node-1) 'IF' /* override breaks in indentedNodes */
->
;
ignoreLineBreaksAfterNode:
[node) pls_expr & [node+1) 'THEN' /* override breaks set in indentedNodes */
->
;SET SERVEROUTPUT ON
BEGIN
FOR r IN (SELECT ename AS emp_name,
sal AS salary
FROM emp
WHERE deptno IN (10, 20))
LOOP
IF r.salary > 2.9e3 THEN
dbms_output.put_line (r.emp_name);
END IF;
END LOOP;
END;
/This is the final result using every callback function. The formatting result does not contain a newline before the THEN on line 9 anymore. Everything looks good now.
Summary
There are simpler ways to produce the final formatting result. However, the goal was to show the impact of every callback function. While the final Arbori program in this blog post produces a reasonably good formatted code, it is far from complete.
If you are interested in alternative formatter settings then I suggest having a look at this GitHub repository.
2 Comments
It is remarkable that you had the patience to reverse engineer all the formatting rules. Initially, I naively thought that just one rule — simple indentations — would be good enough. Then, more and more rules become piling in in somewhat haphazard fashion.
I’m still convinced there don’t have to be that many rules. However, the formatter design should be revised. The key design element must be a rectangular block, and its relative position to the other block, corresponding to the node’s parent, or predecessor in the parse tree. For example, the space before a word or symbol is just a block offset by one character, relative to the predecessor. Vertically aligned piece of code is just a block shifted one line down. The idea of visual elements organized into a tree with spacial transformations relating nodes to their parents is an old one, and it’s leveraged in virtually any 3D and 2D graphics library.
Keep in mind that the formatter can be implemented entirely in JS. The fact that there is the central sequential token processor java function is just a historical artifact. The java callback methods also date to the time when Arbori didn’t support JS callbacks yet.
This is hand waving, of course, because it’s not quite clear what is the mechanism of rendering those code blocks without reliance onto the central sequential token processor. I’d suggest that formatting should be viewed as a translator. Technically, translator is a program which analyses an input text and produces a set of Substitutions. Again, it is immature idea until we figure out how to convert those blocks into Substitutions…
Agreed, the formatter could be implemented in JS, e.g. using SQLDev as a library. However, AFAIK it is not possible to configure an alternative formatter in SQLDev 20.2. You need to provide it as an additional SQLDev extension with a new action which lives beside the existing action “Format” and call it “Beautify” or something similar. Please let me know if I’m missing something here.
It’s interesting to hear that you are thinking about changing the way how the code is formatted using approaches from graphics libraries. I was working on a formatter for PL/SQL myself. It was based on our Trivadis parser produced by Xtext. The formatter used the “old” formatter API and produced only satisfying results for some chosen use cases. In other words, the formatter was never complete. I did not found the time to move it to the new formatter API which contains very interesting concepts: autowrap with handler, conditional formatting, pattern-aware formatting and table-based formatting. However, I stopped working on this project as SQLDev 4.2 came out and it was clear the SQLDev team has taken actions to improve the formatter significantly.
While I very much like the formatter capabilities that come with the exposure of the Arbori program, I do not think it is something a typical SQL Developer (person) should care about. I think the “Advanced Settings” should be enough to get the desired result or a result that is similar to the desired one and therefore good enough. Changing or better extending the provided Arbori program should be the last resort. It’s worth to look at the formatter settings of other PL/SQL IDEs in that context. Here are two screenshots. One of Allround Automations PL/SQL Developer and the other of Quest TOAD:
The screenshots show two things.
By exposing the Arbori program and allowing to change it, SQLDev provides far more options than any other IDE. However, it is not that easy to master and to maintain it (thinking about merging my Arbori program with the one provided by a new SQLDev version). And therefore providing more options outside of the Arbori program to configure the formatter would be very much appreciated. This should work with the current model and also with a future model which might be based on blocks and substitutions.
Thank you for taking the time to comment on this blog post and I look forward to the improvements of future versions of SQLDev, especially in the area of code formatting.