

The merge statement allows you to insert, update and delete rows in the target table in one go. This is great. However, the delete part does not work as expected. Is it a bug? No, it works exactly as documented. Nonetheless, I was not aware of this for years. Let’s take a look at this with an example.
Setup
We create a table t (target) with three rows and a table s (source) with 4 rows. To log DML events we create some after row triggers on table t.
create table t (
id integer not null primary key,
c1 varchar2(20) not null
);
insert into t values (1, 'original 1');
insert into t values (2, 'original 2');
insert into t values (3, 'original 3');
create table s (
id integer not null,
op varchar2(1) not null check (op in ('I', 'U', 'D')),
c1 varchar2(20) not null
);
insert into s values (1, 'U', 'original 1');
insert into s values (2, 'U', 'changed 2');
insert into s values (3, 'D', 'deleted 3');
insert into s values (4, 'I', 'new 4');
create or replace trigger t_ar_i after insert on t for each row
begin
sys.dbms_output.put_line('inserted id ' || :new.id);
end;
/
create or replace trigger t_ar_u after update on t for each row
begin
sys.dbms_output.put_line('updated id ' || :old.id);
end;
/
create or replace trigger t_ar_d after delete on t for each row
begin
sys.dbms_output.put_line('deleted id ' || :old.id);
end;
/Insert, Update, Delete via Merge
Now, we can run this script:
set serveroutput on size unlimited
merge into t
using s
on (t.id = s.id)
when matched then
update
set t.c1 = s.c1
delete
where op = 'D'
when not matched then
insert (t.id, t.c1)
values (s.id, s.c1);
select * from t;
rollback;updated id 1
updated id 2
updated id 3
deleted id 3
inserted id 4
4 rows merged.
ID C1
---------- --------------------
1 original 1
2 changed 2
4 new 4
Rollback complete.The merge statement applied the insert, update and delete operation in the target table t. The result in table t is what we expect.
However, when I look at the output of the DML triggers I do not like the following things:
- The row with
id1 was updated, even if the columnc1did not change. This update is unnecessary and should be avoided, right? - The row with
id3 was updated and then deleted. Updating a row and then deleting it? The first update does not seem necessary, right?
Update Filter
The merge_update_clause documents an optional where_clause for the update part of a merge statement.
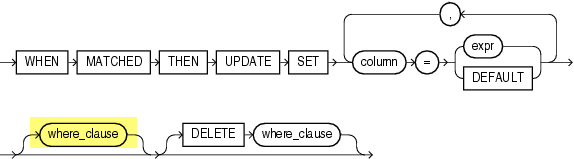
Let’s try that to avoid the unnecessary updates.
set serveroutput on size unlimited
merge into t
using s
on (t.id = s.id)
when matched then
update
set t.c1 = s.c1
where op = 'U'
and t.c1 != s.c1
delete
where op = 'D'
when not matched then
insert (t.id, t.c1)
values (s.id, s.c1);
select * from t;
rollback;updated id 2
inserted id 4
2 rows merged.
ID C1
---------- --------------------
1 original 1
2 changed 2
3 original 3
4 new 4
Rollback complete.Good, no more unnecessary updates. But now we have a new issue. The row with id 3 is not deleted. It looks like the delete part of the merge statement is ignored.
The Fine Print
I thought this was a bug and opened a service request some days ago. The friendly and patient support engineer directed me to this excerpt of the merge_update_clause in the SQL Language Reference of the Oracle Database 19c:
Specify the
DELETE where_clauseto clean up data in a table while populating or updating it. The only rows affected by this clause are those rows in the destination table that are updated by the merge operation.
So, clearly not a bug. The second sentence can be visualized as a Venn diagram:

First Update Then Delete
So we have learned that we must first update a row before we can delete it when we use a merge statement. However, we can still avoid unnecessary updates if the row does not need to be deleted.
Let’s update our script once more:
set serveroutput on size unlimited
merge into t
using s
on (t.id = s.id)
when matched then
update
set t.c1 = s.c1
where t.c1 != s.c1
or op = 'D'
delete
where op = 'D'
when not matched then
insert (t.id, t.c1)
values (s.id, s.c1);
select * from t;
rollback;updated id 2
updated id 3
deleted id 3
inserted id 4
3 rows merged.
ID C1
---------- --------------------
1 original 1
2 changed 2
4 new 4
Rollback complete.Looks good!
The update of the row with id 1 was suppressed because the c1 column did not change. The row with id 2 was changed, a new row with id 4 was inserted and the row with id 3 is gone. We just have to live with the prior update of id 3.
Conclusion
I imagine I’m not the only one who would have expected the merge statement to behave differently. Especially after watching How to UPSERT (INSERT or UPDATE) rows with MERGE in Oracle Database by Chris Saxon. He also mentioned “delete” here and here.
Remember:
Delete only processes rows that were updated.
— Chris Saxon
1 Comment
Thank you so much Philipp!! Great information! I was not aware of this before.