

Introduction
An island grammar focuses only on a small part of a grammar. The island represents the small, interesting part and the sea the rest. In this blog post, I explain the components of an island grammar for SQL scripts named IslandSQL. In the first iteration, we focus on the select statement. Everything else is not of interest for the time being.
Use Case
Let’s assume we want to write an extension for Visual Studio Code that can find text in select statements within SQL files of a workspace. So what is the difference to VSCode’s integrated text search? Well, the text search does not know what a select statement is. It finds occurrences of the search text in all kinds of places. In fact, identifying a select statement is not as easy as one might think.
Let’s look at an example.
/* select * from t1; */
-- select * from t2;
remark select * from t3;
prompt select * from t4;
begin
sys.dbms_output.put_line('irrelevant: select * from t5;');
end;
/
create or replace procedure p is
begin
$if false $then irrelevant: select * from t6; $end
null;
end;
/This SQL script does not contain relevant select statements. A select statement within a comment is hardly relevant. The same is true for select statements in remark and prompt commands. And I consider select statements within string literals and conditional compilation text also as irrelevant, at least in this example.
So let’s look at another example:
-- simple
select * from dept;
-- subquery_factoring_clause
with
d as (
select * from dept
)
select * from d;
-- plsql_declarations
with
function e_count (in_deptno in dept.deptno%type) return integer is
l_count integer;
begin
select count(*)
into l_count
from emp;
return l_count;
end e_count;
select deptno, e_count(deptno)
from dept
/
-- unterminated
select * from deptThis example script contains four select statements. As you can see, a select statement does not necessarily need to start with the select keyword. Furthermore a select statement can end on semicolon or slash or EOF (end-of-file). In fact, when using plsql_declarations the statement must end on a slash (or EOF).
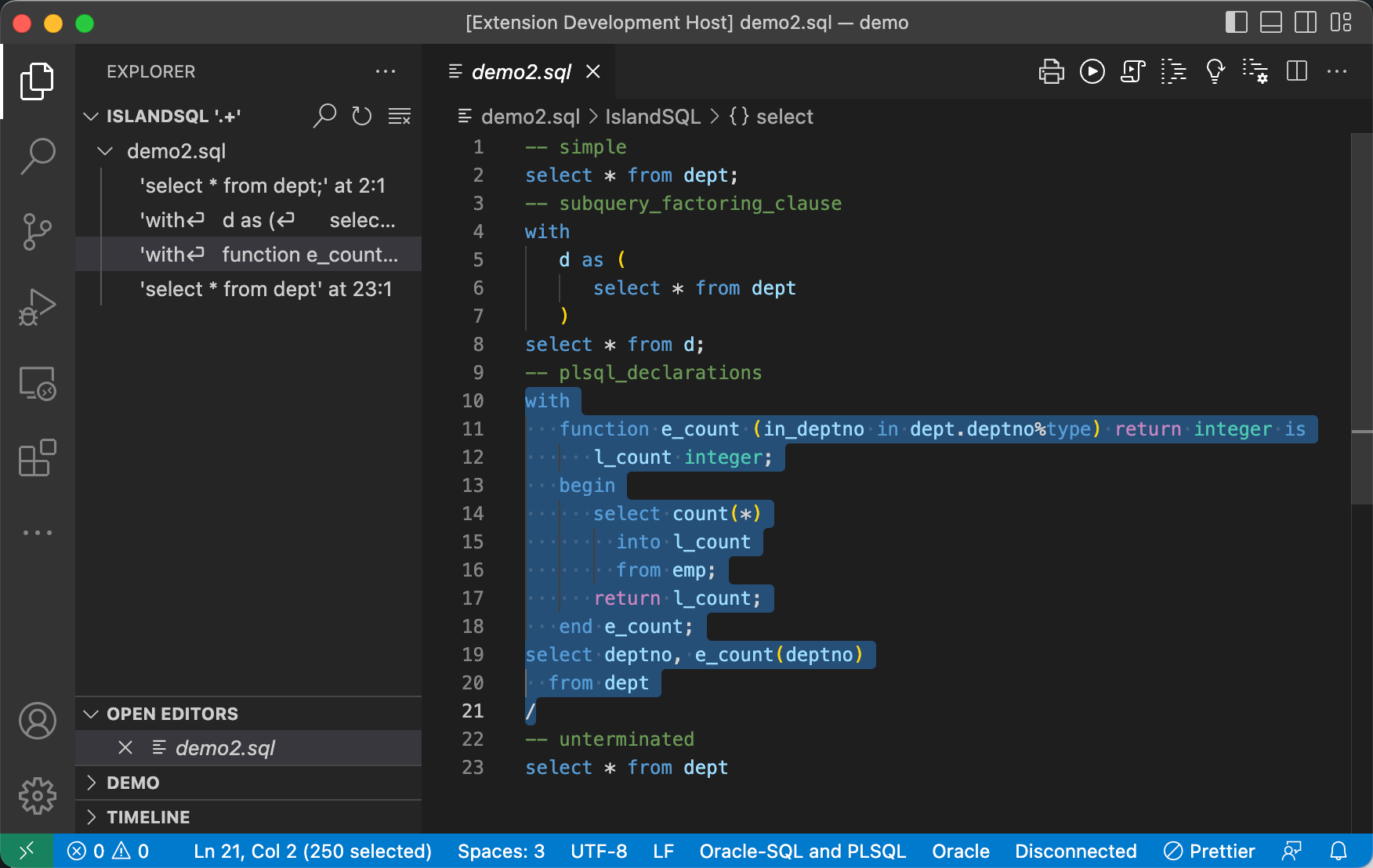
Here’s a screenshot of the VSCode extension after searching for the regular expression .+ in the demo workspace, highlighting the third search result.
Lexer Grammar
The responsibility of the lexer is to convert a stream of characters to a stream of tokens. We use ANTLR 4 to generate our lexer with Java as the target language.
Here’s the grammar definition for our lexer.
lexer grammar IslandSqlLexer;
options {
superClass=IslandSqlLexerBase;
caseInsensitive = true;
}
/*----------------------------------------------------------------------------*/
// Comments and alike to be ignored
/*----------------------------------------------------------------------------*/
ML_COMMENT: '/*' .*? '*/' -> channel(HIDDEN);
SL_COMMENT: '--' .*? (EOF|SINGLE_NL) -> channel(HIDDEN);
REMARK_COMMAND:
{isBeginOfCommand()}? 'rem' ('a' ('r' 'k'?)?)?
(WS SQLPLUS_TEXT*)? SQLPLUS_END -> channel(HIDDEN)
;
PROMPT_COMMAND:
{isBeginOfCommand()}? 'pro' ('m' ('p' 't'?)?)?
(WS SQLPLUS_TEXT*)? SQLPLUS_END -> channel(HIDDEN)
;
STRING:
'n'?
(
(['] .*? ['])+
| ('q' ['] '[' .*? ']' ['])
| ('q' ['] '(' .*? ')' ['])
| ('q' ['] '{' .*? '}' ['])
| ('q' ['] '<' .*? '>' ['])
| ('q' ['] . {saveQuoteDelimiter1()}? .+? . ['] {checkQuoteDelimiter2()}?)
) -> channel(HIDDEN)
;
CONDITIONAL_COMPILATION_DIRECTIVE: '$if' .*? '$end' -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Islands of interest on DEFAULT_CHANNEL
/*----------------------------------------------------------------------------*/
PLSQL_DECLARATION:
{isBeginOfStatement()}? 'with' WS
('function'|'procedure') SQL_TEXT*? PLSQL_DECLARATION_END
;
SELECT:
{isBeginOfStatement()}? ('with'|('(' WS?)* 'select') SQL_TEXT*? SQL_END
;
/*----------------------------------------------------------------------------*/
// Whitespace
/*----------------------------------------------------------------------------*/
WS: [ \t\r\n]+ -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Any other token
/*----------------------------------------------------------------------------*/
ANY_OTHER: . -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Fragments to name expressions and reduce code duplication
/*----------------------------------------------------------------------------*/
fragment SINGLE_NL: '\r'? '\n';
fragment CONTINUE_LINE: '-' [ \t]* SINGLE_NL;
fragment SQLPLUS_TEXT: (~[\r\n]|CONTINUE_LINE);
fragment SQL_TEXT: (ML_COMMENT|SL_COMMENT|STRING|.);
fragment SLASH_END: SINGLE_NL WS* '/' [ \t]* (EOF|SINGLE_NL);
fragment PLSQL_DECLARATION_END: ';'? [ \t]* (EOF|SLASH_END);
fragment SQL_END:
EOF
| (';' [ \t]* SINGLE_NL?)
| SLASH_END
;
fragment SQLPLUS_END: EOF|SINGLE_NL;Lexer Options
On lines 3-6 we define the grammar options.
The first option defines the superclass that the generated lexer class should extend from. We use this class to define semantic predicates that can be used in the lexer grammar. Semantic predicates are very powerful. However, they bind a grammar to a target language. Of course, you can implement a superclass in different target languages. But would you want to do that for every supported target language?
The second option defines the grammar as case-insensitive. This simplifies the grammar. We can simply write select instead of S E L E C T where every letter is a fragment (e.g. fragment S: [sS];).
Channels
A token can be either ignored (skipped) or placed on a channel. ANTLR provides by default the following two channels:
DEFAULT_CHANNEL: for visible tokens that are relevant to the parser grammarHIDDEN: for tokens that are not relevant to the parser grammar
We do not skip tokens in this grammar. This has the advantage that we can access hidden tokens when we need to. For example, for accessing hints or for lossless serialisation of chosen parts.
Comments and Alike
On lines 8-33, we define hidden tokens using lexer rules.
The notation for the token definitions should be familiar to those with regular expression experience.
— Terence Parr, The Definitive ANTLR 4 Reference, 2nd edition, page 36
The tokens defined in this section are similar to comments and therefore should be ignored and placed on the hidden channel.
The order of the rules is important in case of conflicting definitions. The first rule wins. ML_COMMENT defines a multiline comment starting with /* and ending with */. The rules defined afterwards cannot define tokens that are a subset of ML_COMMENT. For example, a select statement within a ML_COMMENT is not visible for subsequent rules. This is the reason for the rules in this section. We want to hide select statements within comments and alike.
However, it is possible to define a token that contains a ML_COMMENT, e.g. in a select statement.
Islands of Interest
You find the islands of interest on lines 35-45. The rule PLSQL_DECLARATION covers the select statement with a plsql_declarations clause. And the rule SELECT covers the select statement without a plsql_declarations clause. Identifying the end of the select statement is a bit tricky.
This definition works in many cases, but it will falsely match subqueries in other statements such as insert, update, delete, merge, etc. In such cases, everything up to the next semicolon is considered part of the select statement. We will address this flaw in a future version of the grammar.
How do we ignore semicolons in comments and strings? By using the fragment SQL_TEXT. A SQL_TEXT is either a ML_COMMENT, a SL_COMMENT, a STRING or any other character (.). Again, the order is important. The lexer considers comments and strings as single tokens. A semicolon in comments or strings is not visible. As a result, a semicolon in comments or strings will not be interpreted as the end of a select statement.
Did you wonder why I use ANTLR instead of regular expressions? Well, it’s simply not possible to write a regular expression that can match a complete select statement ending on a semicolon while ignoring the semicolons in comments and strings. Simply put, ANTLR is more powerful.
These two rules produce a single token for the whole select statement. This is simple and enough for our current use case. However, in the coming versions of the grammar, we will rewrite this section to parse a select statement completely and address the issues with subqueries in other statements.
Whitespace
The WS rule on line 51 defines whitespace characters. They are not relevant for the parser, hence we put them on the HIDDEN channel.
Other Tokens
The ANY_OTHER rule on line 57 covers any other character. They are not relevant for the parser and we put them also on the HIDDEN channel.
Fragments
And finally, on lines 59-74 we have fragments. A fragment allows one to name an expression and use the fragment name instead of the expression in other fragments or rules. This makes the grammar more readable without introducing additional token types.
Parser Grammar
We use the output of the lexer – the token stream – in the parser. By default, only the tokens on the DEFAULT_CHANNEL are visible in the parser grammar. This makes the grammar quite simple.
parser grammar IslandSqlParser;
options {
tokenVocab=IslandSqlLexer;
}
/*----------------------------------------------------------------------------*/
// Start rule
/*----------------------------------------------------------------------------*/
file: selectStatement* EOF;
/*----------------------------------------------------------------------------*/
// Rules for reduced SQL grammar (islands of interest)
/*----------------------------------------------------------------------------*/
selectStatement: PLSQL_DECLARATION | SELECT;Parser Options
On line 4 we include the token vocabulary based on the lexer grammar. The vocabulary defines integer values for each token type, e.g. PLSQL_DECLARATION=7 or SELECT=8. The token stream uses these integer values to identify token types. Integers are shorter than their string counterparts and therefore use fewer resources.
Start Rule
You find the start rule file on line 11. This is the entry point for the parser. The root node of the parse tree.
A file may contain an unbounded number of selectStatement rules. And a file ends on the pseudo tokenEOF (end-of-file). This way we ensure that the parser reads the complete file.
Select Statement
On line 17 the selectStatement is defined either as a PLSQL_DECLARATION or SELECT token.
That’s it. All other tokens are hidden and invisible to the parser.
Furthermore, it’s not possible to produce a parse error with this grammar. Everything that is not a selectStatement is on the hidden channel and irrelevant.
Interpreter
ANTLR is a parser generator. It takes the lexer and parser grammar as input and produces a lexer and parser in a chosen target language as output.
However, there are also ANTLR interpreters. As a plugin in IDEs such as IntelliJ, as a standalone application or as a web application. After pasting the grammers into the UI you can play with it. Here’s a screenshot of the web variant of ANTLR lab.
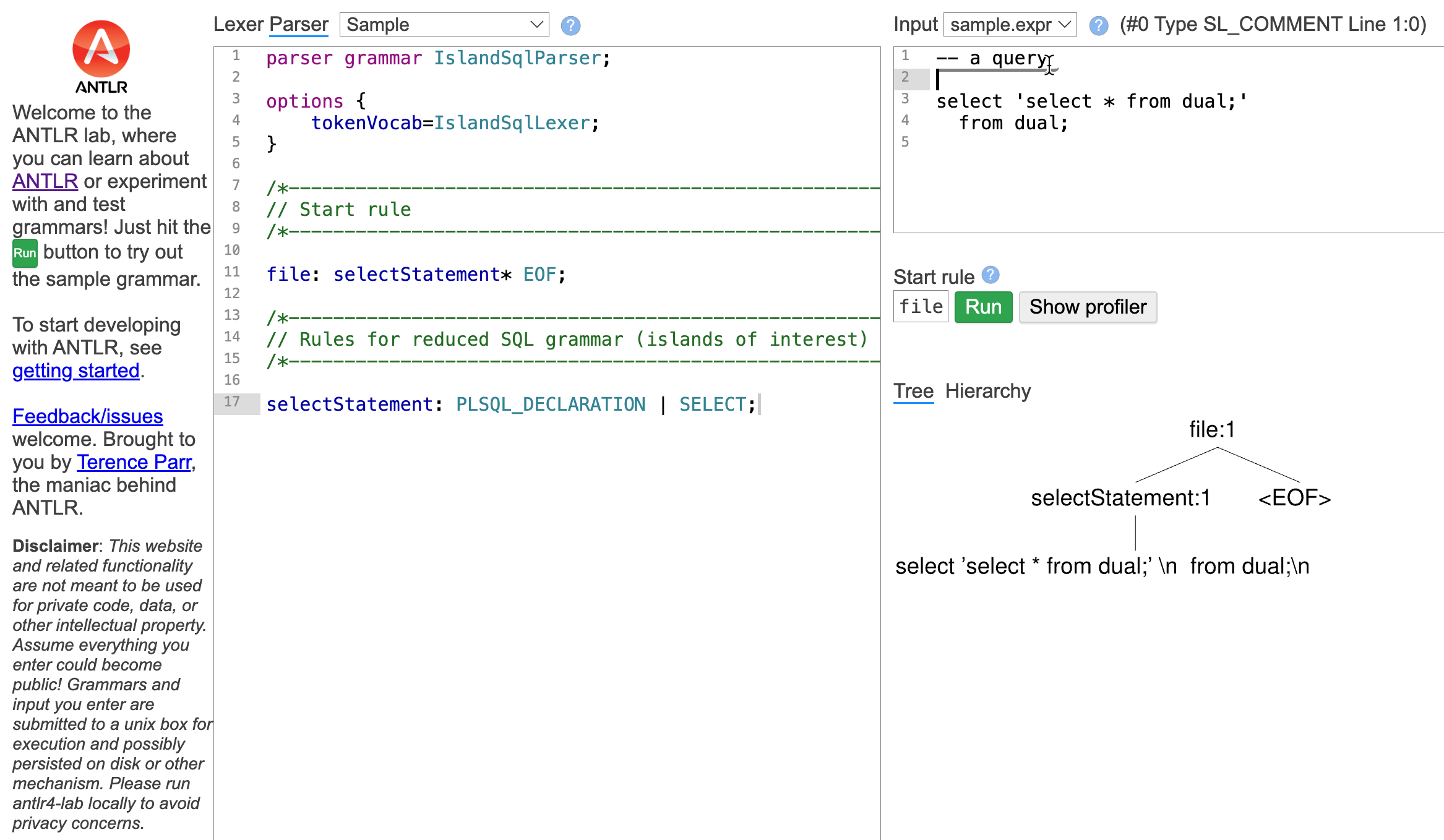
What about semantic predicates? – The interpreter acts as the call returned true. As a result, for example, xselect * from dual; is falsely recognized as a select statement. Nevertheless, this is usually good enough to explore most parts of an ANTLR grammar.
IslandSQL on GitHub
The source code of the IslandSQL parser is available on GitHub, licensed under the Apache License, Version 2.0.
However, you will not find any test cases in this repo. I have written 92 test cases for the initial version 0.1.0. They are stored in a private repository. I do not plan to release them. It’s a way to make an unfriendly fork harder. Not right now. But once the grammar has evolved to cover a significant subset of SQL of the relevant database management systems, the situation might be different.
IslandSQL on Maven Central
The IslandSQL parser is available on Maven Central. This makes integration into your preferred build system easy.
And using the parser is also easy. Here is an example:
import ch.islandsql.grammar.IslandSqlDocument;
import ch.islandsql.grammar.IslandSqlParser;
class Demo {
public static void main(String[] args) {
var doc = IslandSqlDocument.parse("""
/* select * from t1; */
-- select * from t2;
rem select * from t3;
prompt select * from t4;
-- simple
select * from dept;
-- subquery_factoring_clause
with d as (select * from dept) select * from d;
-- other statements
delete from t5;
update t6 set c1 = null;
commit;
""");
System.out.println(doc.getFile().getText());
System.out.println("----------");
doc.getFile().children.forEach(child -> System.out.print(child.getText()));
System.out.println("\n----------");
doc.getAllContentsOfType(IslandSqlParser.SelectStatementContext.class)
.forEach(stmt -> System.out.print(stmt.getText()));
}
}The output of the main method is:
select * from dept;
with d as (select * from dept) select * from d;
<EOF>
----------
select * from dept;
with d as (select * from dept) select * from d;
<EOF>
----------
select * from dept;
with d as (select * from dept) select * from d;IslandSQL on Visual Studio Code Marketplace
The extension for IslandSQL is available in the Visual Studio Code Marketplace. You can install it directly from any VS Code installation.
Agreed, this extension is currently of limited value. However, it was a good opportunity to learn about VSCode extension development and how to use the tooling around Microsoft’s Language Server Protocol (LSP) to integrate a grammar that is written in Java.
I am sure I can use this knowledge for other projects like utPLSQL once SQL Developer for VScode is available.
Outlook
I plan to extend the IslandSQL grammar step by step and blog about the progress. At some point, it will be necessary to move the logic from the lexer to the parser. Before that, I’ll be working on the lexer side a bit longer.
Adding the missing DML statements to the grammar will be the next item on my to-do list.
Another topic is utPLSQL. The utPLSQL annotations in package specifications could be easily parsed with a dedicated island grammar. We could visualise test suite hierarchies in the IDE and also consider tags. Of course, we would duplicate some of utPLSQL’s code in the database. The advantage of such an approach is that we know where a test package is located in the file system. This helps in navigating to the right place, e.g. after test execution failures and could greatly improve the experience of file-based development (compared to SQL Developer). I am looking forward to the next generation of SQL Developer based on VS Codium, where such an extension would bring the most value.
1 Comment
[…] the last episode we build the initial version of IslandSQL. An Island grammar for SQL scripts covering select […]