

The latest version 3.1 of the Trivadis PL/SQL & SQL Coding Guidelines has 150 pages. More than 90 additional pages compared to version 2.0. Roger Troller did a tremendous job in updating and extending an already comprehensive document while making it simpler to read and easier to understand. In this post, I will emphasise some changes I consider relevant.
New Guideline Categorisation Scheme
In version 2.0 coding guidelines are categorised by icons for information, caution, performance relevance, maintainability and readability. A guideline is associated exactly with one icon. Here’s an example:

In version 3.1 the characteristics for changeability, efficiency, maintainability, portability, reliability, reusability, security and testability as defined by the Software Quality Assessment based on Lifecycle Expectations (SQALE) methodology are used to categorise guidelines. A guideline is associated with one or more SQALE characteristics. Additionally a guideline is assigned to a severity (blocker, critical, major, minor, info). So guidelines are categorised in two dimensions: SQALE characteristics and severity. These categorisations are used to filter guidelines in SonarQube or PL/SQL Cop to be enabled or disabled. It’s not by chance that SonarQube is using exactly these categorisations.
Here’s the same example as above using this new guideline categorisation scheme:
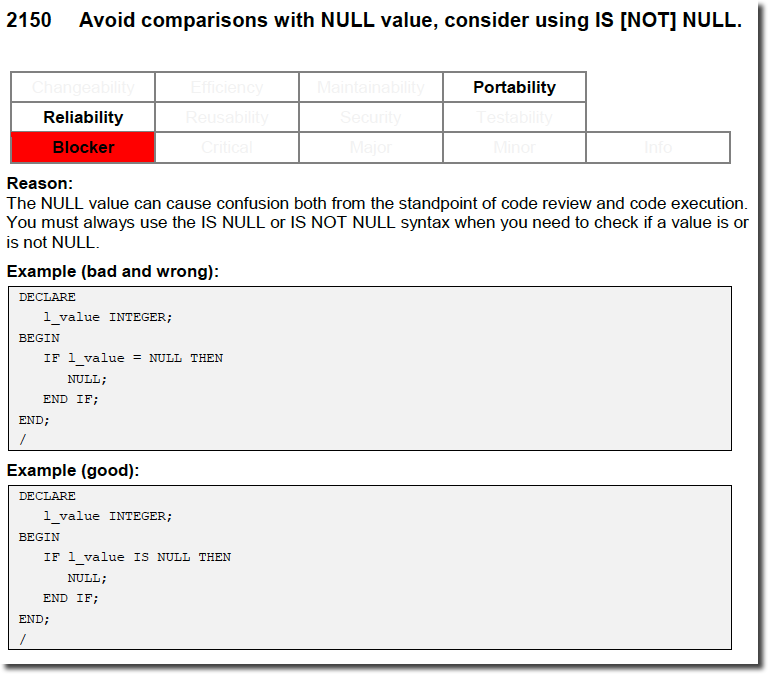
In this excerpt, you see other changes as well. The reference to the CodeXpert rule is gone, guideline 12 got a new identifier 2150 and there is a good and bad example.
Good and Bad Examples for Every Guideline
In version 2.0 some guidelines had no examples, some just an excerpt of an example, some just a good and some just a bad example. Now in version 3.1 almost every guideline has a complete bad and a complete good example. By complete I mean that they are executable in SQL*Plus, SQLcl or within your IDE of choice. Why “almost”? For example, there is this guideline 65/7210 which says “Try to keep your packages small. Include only a few procedures and functions that are used in the same context”. So, in some cases, it is just not feasible/helpful to include a complete example.
For me as the guy who is responsible for writing rules to check the compliance of the guidelines, good and bad examples are essential for unit testing. Such examples also help the developer to understand guidelines. That’s why we include these examples in PL/SQL Cop.
New Guidelines
Besides some changes in the categorisation and presentation of the guidelines, there are some new guidelines which I’d like to mention here:
| ID | Guideline | Severity | SQALE Characteristics |
|---|---|---|---|
| 2230 | Try to use SIMPLE_INTEGER datatype when appropriate. | Minor | Efficiency |
| 3150 | Try to use identity columns for surrogate keys. | Minor | Maintainability, Reliability |
| 3160 | Avoid virtual columns to be visible. | Major | Maintainability, Reliability |
| 3170 | Always use DEFAULT ON NULL declarations to assign default values to table columns if you refuse to store NULL values. | Major | Reliability |
| 3180 | Always specify column names instead of positional references in ORDER BY clauses. | Major | Changeability, Reliability |
| 3190 | Avoid using NATURAL JOIN. | Major | Changeability, Reliability |
| 5010 | Try to use a error/logging framework for your application. | Critical | Reliability, Reusability, Testability |
| 7460 | Try to define your packaged/standalone function to be deterministic if appropriate. | Major | Efficiency |
| 7810 | Do not use SQL inside PL/SQL to read sequence numbers (or SYSDATE) | Major | Efficiency, Maintainability |
| 8120 | Never check existence of a row to decide whether to create it or not. | Major | Efficiency, Reliability |
| 8310 | Always validate input parameter size by assigning the parameter to a size limited variable in the declaration section of program unit. | Minor | Maintainability, Reliability, Reusability, Testability |
| 8410 | Always use application locks to ensure a program unit only running once at a given time. | Minor | Efficiency, Reliability |
| 8510 | Always use dbms_application_info to track programm process transiently | Minor | Efficiency, Reliability |
Deprecated Guidelines
Guideline 54 “Avoid use of EXCEPTION_INIT pragma for a -20,NNN error” is not part of the document anymore.
New Guideline Identifiers
All guidelines got a new identifier. The first digit identifies the chapter of the document, e.g. “1” for “4.1 General”, “2” for “4.2 Variables & Types”, etc. The second digit is reserved for the sub-chapters and the remaining digits are just for ordering purposes. The gaps in the numbering scheme should allow to add future guidelines at the right place without renumbering everything (again).
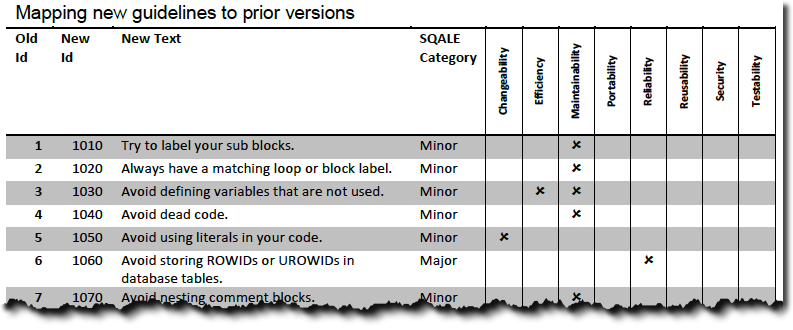
There is an appendix to map old guideline identifiers to new ones. This should simplify the change to version 3.1. Here’s an excerpt:
Tool Support
PL/SQL Cop is mentioned in the guidelines. However, currently, only the Trivadis PL/SQL & SQL Guidelines Version 2.0 are supported. But sometime in Q4 of 2016, an update supporting version 3.1 should be available.
Download
Get your copy of the Trivadis PL/SQL & SQL Guidelines Version 3.1 from here.