

Are you reluctant to use regular expressions in SQL? Then continue reading. Examples helped me to understand regular expressions years ago. Thus I hope this collection of simple examples and the tooling tips will encourage you to use regular expressions. It’s not as complicated as it looks at first glance. Once you get used to the syntax, it’s fun to figure out the right match pattern.
Use Cases in SQL
The Oracle Database supports regular expression since version 10g Release 1. You may use it to:
- Validate an input using
regexp_like; - Find patterns in text using
regexp_count,regexp_instrandregexp_substr; - Find and replace patterns in text using
regexp_replace.
Finding text using regular expressions is known as pattern matching. Those who understand regular expressions will quickly find their way around row pattern matching, since the pattern syntax is very similar.
The Text
All examples use this famous quote from Henry Ford:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
All matches are highlighted .
Single Character
The simplest match pattern (regular expression without match parameters) is a single character. There are some characters with a special meaning such as ., \, ?, *, +, {, }, [, ], ^, $, |, (, ). We deal with these characters later. However, as long as you do not use one of these characters, the match pattern behaves like the substring parameter in the well-known instr function.
Match pattern: t returns 5 matches:
"Whet her you t hink you can or t hink you can't - you are right ."
-- Henry Ford (1863 - 1947)
The following query produces a row per match. It can be used in the subsequent examples as well (with an adapted match pattern).
WITH
base AS (
SELECT '"Whether you think you can or think you can''t - you are right."'
|| chr(10) || '-- Henry Ford (1863 - 1947)' AS text,
't' AS pattern
FROM dual
)
-- main
SELECT regexp_substr(text, pattern, 1, level) AS matched_text,
regexp_instr(text, pattern, 1, level) AS at_pos
FROM base
CONNECT BY level <= regexp_count(text, pattern);
MATCHED_TEXT AT_POS
-------------------- ----------
t 5
t 14
t 31
t 45
t 61The named subquery base provides the text and the match pattern. This way the expressions do not have to be repeated. The regexp_count function on line 12 limits the result to 5 rows. The regexp_substr function call on line 9 returns the matched text and the regexp_instr function call on line 10 the position.
Multiple Characters
A string is just a series of characters.
The match pattern thin returns 2 matches:
"Whether you thin k you can or thin k you can't - you are right."
-- Henry Ford (1863 - 1947)
Any Character Wildcard .
A dot . matches per default any character except newline chr(10).
The match pattern c.n returns 2 matches:
"Whether you think you can or think you can 't - you are right."
-- Henry Ford (1863 - 1947)
Escape Character \
If we want to match special characters such as a dot . than we have to escape it with a \.
The match pattern \. returns 1 match:
"Whether you think you can or think you can't - you are right. "
-- Henry Ford (1863 - 1947)
0..1 Matches (Optionality) ?
We use a ? to express that a character (or a group of characters) is optional.
The match pattern c?.n returns 5 matches:
"Whether you thin k you can or thin k you can 't - you are right."
-- Hen ry Ford (1863 - 1947)
You see that the c is part of a match in can, but h before in is not.
0..n Matches *
We use a * to express that a character (or a group of characters) can appear between 0 and n times. n is not defined and is in fact unbounded.
The match pattern you.*n returns 1 match:
"Whether you think you can or think you can 't - you are right."
-- Henry Ford (1863 - 1947)
Please note that the first match was not you thin. Rather it was extended to the last n in the first line. This behaviour is called greedy.
Nongreedy Matches ?
We use a ? at the end of the quantifier (?, *, +, {}) to match as few as possible.
The match pattern you.*?n returns 3 matches:
"Whether you thin k you can or think you can 't - you are right."
-- Henry Ford (1863 - 1947)
Please note that we now have three matches. This behavior is called nongreedy or reluctant or lazy.
1..n Matches +
We use a + to express that a character (or a group of characters) can appear between 1 and n times. n is not defined and is in fact unbounded.
The match pattern -+ returns 3 matches:
"Whether you think you can or think you can't - you are right."-- Henry Ford (1863 - 1947)
Exact Match {n}
We use {n} to express that a character (or a group of characters) must appear exactly n times.
The match pattern -{2} returns 1 match:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Match Ranges {m,n}
We use {m,n} to express that a character (or a group of characters) must appear between m and n times. You may skip the definition for n to express an unbounded value.
The match pattern -{1,3} returns 3 matches:
"Whether you think you can or think you can't - you are right.”
-- Henry Ford (1863 - 1947)
Alphanumeric Wildcard \w
A \w matches any alphanumeric character.
The match pattern \w+ returns 17 matches:
"Whether you think you can or think you can 't - you are right ."
-- Henry Ford (1863 - 1947 )
Non-alphanumeric Wildcard \W
A \W matches any non-alphanumeric character. Please note that the match pattern is case-sensitive. The upper case letter W leads to the opposite result than the lower case letter w. This is an essential principle for match patterns.
The match pattern \W+ returns 18 matches:
" Whether you think you can or think you can' t - you are right."
-- Henry Ford ( 1863 - 1947)It’s important to note that the newline chr(10) is part of match 14.
Digit Wildcard \d
A \d matches any digit (0 to 9).
The match pattern \d+ returns 2 matches:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947 )
Non-digit Wildcard \D
A \D matches any non-digit character. Please note that the match pattern is case-sensitive. The upper case letter D leads to the opposite result than the lower case letter d. This is an essential principle for match patterns.
The match pattern \D+ returns 3 matches:
"Whether you think you can or think you can't - you are right."
-- Henry Ford ( 1863 - 1947)
It’s important to note that the newline chr(10) is part of the first match.
Whitespace Wildcard \s
A \s matches any whitespace character. Whitespace are:
- spaces
chr(32) - horizontal tabs
chr(9) - carriage returns
chr(13) - line feeds/newlines
chr(10) - form feeds
chr(12) - vertical tabs
chr(11)
The match pattern \s+ returns 18 matches:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
It’s important to note that the match 13 is a newline chr(10).
Non-whitespace Wildcard \S
A \S matches any non-whitespace character. Please note that the match pattern is case-sensitive. The upper case letter S leads to the opposite result than the lower case letter s. This is an essential principle for match patterns.
The match pattern \S+ returns 19 matches:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Character Class [xyz]
A character class is a list of characters defined within brackets. You can also use a hyphen - to specify a range of characters. For example [0-9] which is equivalent to \d. You can combine ranges and single characters.
The match pattern [a-zA-Z']+ returns 14 matches:
"Whether you think you can or think you can't - you are right ."
-- Henry Ford (1863 - 1947)
Negated Character Class [^xyz]
A negated character class matches all characters that are not defined within brackets. A ^ at the first position within the brackets defines a negated character class.
The match pattern [^a-zA-Z']+ returns 15 matches:
" Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
It’s important to note that the newline chr(10) is part of match 13.
Beginning of Line or String ^
A ^ matches the position before the first character within a line or string. By default a text is treated as a string.
The match pattern ^- returns 0 matches:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
It’s important to note that by default the whole text is treated as a single line. Hence ^ means beginning of string. And the string starts with a " and not with a -. Therefore no matches.
Multiline Mode m
A regular expressions has two parts. The first part is the match pattern. The second part are match parameters. Until now we have not defined match parameters, hence the default has been used. The match parameter m will logically change the text from a single line to an array of lines.
The match pattern ^- with the match parameter m returns 1 match:
"Whether you think you can or think you can't - you are right."
- - Henry Ford (1863 - 1947)
The next query produces a row per match as the query above, but applies the match parameter m.
WITH
base AS (
SELECT '"Whether you think you can or think you can''t - you are right."'
|| chr(10) || '-- Henry Ford (1863 - 1947)' AS text,
'^-' AS pattern,
'm' AS param
FROM dual
)
-- main
SELECT regexp_substr(text, pattern, 1, level, param) AS matched_text,
regexp_instr(text, pattern, 1, level, 0, param) AS at_pos
FROM base
CONNECT BY level <= regexp_count(text, pattern, 1, param);
MATCHED_TEXT AT_POS
-------------------- ----------
- 65The match parameter is defined on line 6. The regex_substr function call on line 10 and the regex_instr function call on line 11 get this match parameter as an additional input.
You may use this query with adapted match pattern and match parameters to reproduce the results of the subsequent examples.
End of Line or String $
A $ matches the position after the last character within a line or string. By default a text is treated as a string.
The match pattern "$ with the match parameter m returns 1 match:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Ignore Case Mode i
Use the match parameter i for case-insensitive matches.
The match pattern he with the match parameter i returns 3 matches:
"Whe the r you think you can or think you can't - you are right."
-- He nry Ford (1863 - 1947)
Case-sensitive Mode c
Use the match parameter c for case-sensitive matches. This is the default. However, when NLS_SORT is set to a case-insensitive sort order – e.g. BINARY_CI, GENERIC_M_CI, FRENCH_M_CI, etc. – then the default changes to case-insensitive matches.
The match pattern he with the match parameter c returns 2 matches:
"Whe the r you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Period Matches Newline Mode n
Use the match parameter n to change the behavior of the any character wildcard . to match newlines chr(10) as well.
The match pattern .+ with the match parameter n returns 1 match:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Ignore Whitespace in Pattern Mode x
Use the match parameter x to ignore whitespace in match patterns. For long match patterns it might be helpful to add spaces, tabs and newlines to make the regular expressions more readable. By default these whitespace are considered to be part of the match pattern. To ignore them you have to use the x mode. However, whitespace in brackets are always considered, e.g. [ ].
The match pattern h e nr y with the match parameters ix returns 1 match:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
Please note that multiple match parameters (i and x) are used.
Alternatives |
Use a | to express alternative options. The number of options is not limited. The order of the options corresponds to the priority.
The match pattern think|can't|can returns 4 matches:
"Whether you think you can or think you can't - you are right." -- Henry Ford (1863 - 1947)
It’s important to note that the order of the options matter in this case. The match pattern think|can|can't would never match can't. Furthermore, to avoid redundancies in match patterns you would use groups. For example think|can('t)?.
Numbered Groups (xyz)
Use parenthesis – ( and ) – to define groups. You may nest groups as well. The complete match pattern is group 0. All other (sub-)groups are numbered from left to right. You may simply count the number of open parenthesis in a match pattern up to the cursor position of a group to determine the group number.
The match pattern ^("|')(.+)(\1)\s+--\s+(\w+)\s+(\w+)\s+(\((\d+)\s*-\s*(\d+)\))$ returns 1 match:
"Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
The matches for the groups are:
- 0=full match (as shown above)
- 1=
" - 2=
Whether … right. - 3=
" - 4=
Henry - 5=
Ford - 6=
(1863 - 1947) - 7=
1863 - 8=
1947
Please note that the group 3 in the match pattern is referencing the result of the group 1 ("). This means a quote starting with ' must end on ' and a quote starting with " must end on ".
The next query produces a row per group.
WITH
base AS (
SELECT '"Whether you think you can or think you can''t - you are right."'
|| chr(10) || '-- Henry Ford (1863 - 1947)' AS text,
'^("|'')(.+)(\1)\s+--\s+(\w+)\s+(\w+)\s+(\((\d+)\s*-\s*(\d+)\))$' AS pattern
FROM dual
)
-- main
SELECT level-1 AS group_no,
regexp_substr(text, pattern, 1, 1, null, level-1) AS matched_group_text
FROM base
CONNECT BY level <= regexp_count(pattern, '[^\\]?\(') + 1;
GROUP_NO MATCHED_GROUP_TEXT
-------- ----------------------------------------------------------------
0 "Whether you think you can or think you can't - you are right."
-- Henry Ford (1863 - 1947)
1 "
2 Whether you think you can or think you can't - you are right.
3 "
4 Henry
5 Ford
6 (1863 - 1947)
7 1863
8 1947
9 rows selected.The regex_substr function call on line 10 gets the group number as the last input parameter.
Tooling
The match pattern used in the previous example is not that easy to read. Hence I recommend using some tools to build regular expressions. These tools provide quick references and libraries for common regular expressions. And of course, they provide features to test regular expressions and show matches. But they also can explain a regular expression in detail. Here are three of them:
- Expresso is a longtime, reliable companion of mine. This tool has helped me to build and understand many regular expressions. It runs under Windows and is free, but requires registration.
- regular expressions 101 is a popular online regular expressions tester and debugger.
- RegExr is another popular online tool to learn, test and build regular expressions.
Here’s a screenshot of Expresso showing the match results and some explanation of the regular expression.
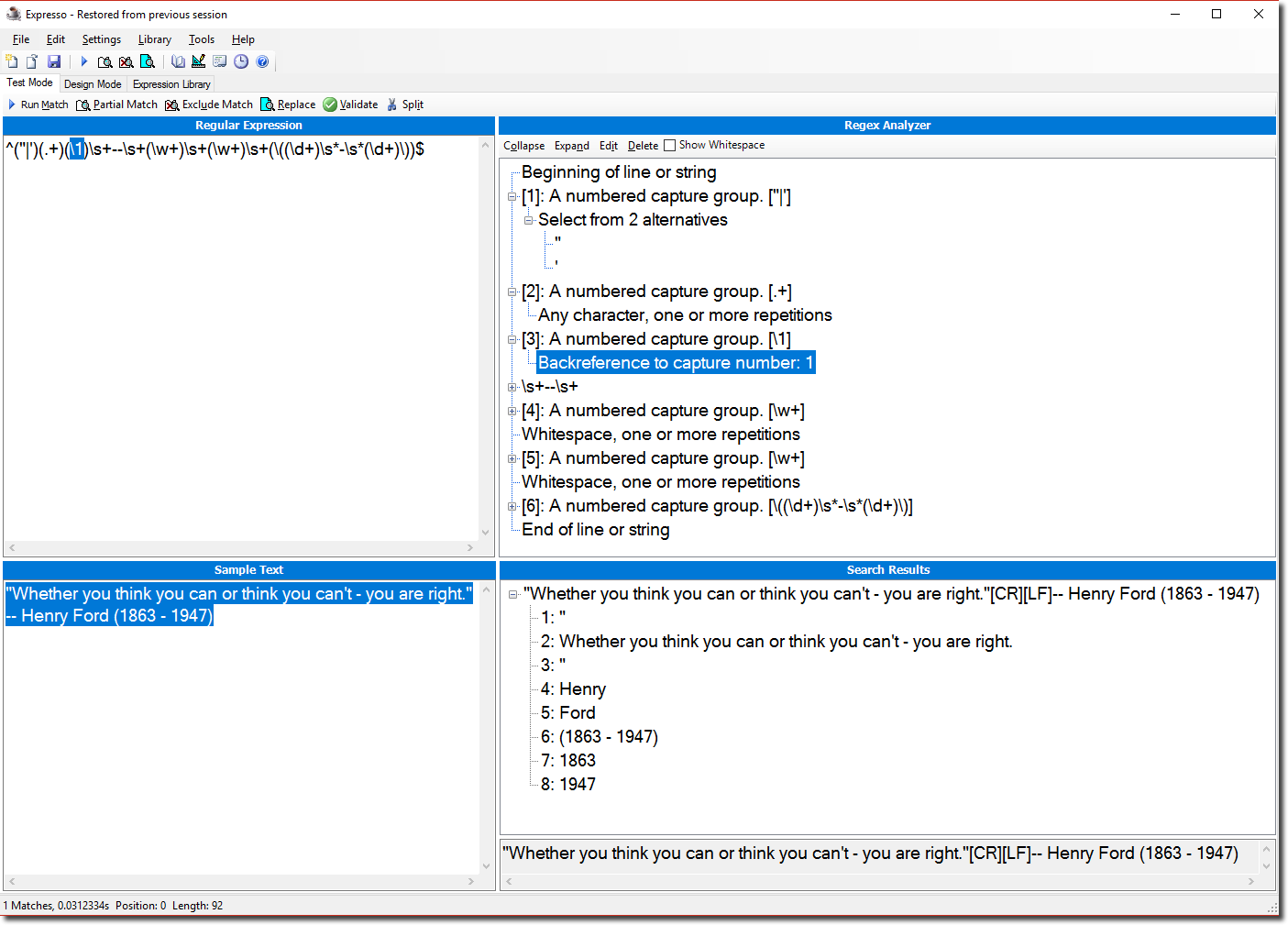
It’s important to note that the regular expressions in the Oracle Database conforms to POSIX with a few extensions influenced by PCRE. So these tools support regular expression features which are not available in Oracle SQL. I miss for example non-capturing groups, lookaheads and some escaped characters (\r, \n, \t, etc.).
Summary
Regular expressions are not self-explanatory. In this post, I covered most of the regular expression grammar that is applicable in SQL functions of an Oracle Database.
- Strings:
t,thin - Greedy quantifiers:
?,*,+,{2},{1, 3} - Nongreedy quantifiers:
??,*?,+?,{2}?,{1, 3}? - Character classes:
.,\.,\w,\W,\d,\D,\s,\S,[a-z],[^a-z] - Positions:
^,$ - Alternatives:
| - Numbered groups:
(abc),\1,\2, …,\9 - Match parameters:
m,i,c,n,x
With a basic knowledge of regular expressions, the available tooling makes building, testing and understanding regular expressions quite easy.