

Do you use parameterless PL/SQL functions in your queries? Did you know that this may cause performance issues? In this blog post, I explain why parameterless functions can be the reason for bad execution plans in any Oracle Database.
I recently had to analyze this problem in a production system and thought it was worth sharing. On the one hand, because we did not find a satisfactory solution and on the other hand because this could change in the future when we start discussing it.
For this blog post, I used an Oracle Database 19c Enterprise Edition, version 19.5.0.0.0 in a Docker environment. However, you can run the scripts in any edition of an Oracle Database 12c Release 1 or later to reproduce the results.
1. Data Setup
We create a user demo with ALTER SESSION and SELECT ANY DICTIONARY privileges as follows:
CREATE USER demo IDENTIFIED BY demo
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON users;
GRANT connect, resource TO demo;
GRANT alter session TO demo;
GRANT select any dictionary TO demo;Then as user demo we create a table t with an index t_ind_idx on column ind
CREATE TABLE t (
id INTEGER GENERATED ALWAYS AS IDENTITY CONSTRAINT t_pk PRIMARY KEY,
ind INTEGER NOT NULL CONSTRAINT ind_ck CHECK (ind IN (0, 1)),
text VARCHAR2(100) NOT NULL
);
CREATE INDEX t_ind_idx ON t (ind);and populated table t with the following anonymous PL/SQL block:
BEGIN
dbms_random.seed(0);
INSERT INTO t (ind, text)
SELECT CASE
WHEN dbms_random.value(0, 999) < 1 THEN
1
ELSE
0
END AS ind,
dbms_random.string('p', round(dbms_random.value(5, 100),0)) AS text
FROM xmltable('1 to 100000');
COMMIT;
END;
/The case expression leads to a skewed distribution of column ind. Only around 0.1% of the rows have a value 1 as the following query shows:
SELECT ind, count(*)
FROM t
GROUP BY ind;
IND COUNT(*)
---------- ----------
1 101
0 99899Therefore we are gathering statistics for table t with a histogram for column ind:
BEGIN
dbms_stats.gather_table_stats(
ownname => user,
tabname => 'T',
method_opt => 'FOR ALL COLUMNS SIZE AUTO FOR COLUMNS SIZE 2 IND'
);
END;
/Now, we can check the histogram with the following query:
SELECT endpoint_value, endpoint_number
FROM user_histograms
WHERE table_name = 'T'
AND column_name = 'IND';
ENDPOINT_VALUE ENDPOINT_NUMBER
-------------- ---------------
0 99899
1 100000Two rows for the two values of column ind. For value 0 we expect 99899 rows (endpoints) and for value 1 we expect 101 rows (100000 – 99899 endpoints). This is 100 percent accurate.
2. Constant Declaration
In the Trivadis PL/SQL & SQL Guidelines we recommend avoiding the use of literals in PL/SQL code. Every time we see a literal in a PL/SQL code we should consider using a constant instead. Often this makes sense because the name of the constant is more meaningful than the literal, making the code more readable and maintainable.
Hence we create the following PL/SQL package for our representation of boolean values in SQL:
CREATE OR REPLACE PACKAGE const_boolean AUTHID DEFINER IS
co_true CONSTANT INTEGER := 1;
co_false CONSTANT INTEGER := 0;
END const_boolean;
/Now we can use these constants in our PL/SQL code as follows:
SET SERVEROUTPUT ON
BEGIN
FOR r IN (
SELECT count(*) AS open_count
FROM t
WHERE ind = const_boolean.co_true
) LOOP
dbms_output.put_line('open: ' || r.open_count);
END LOOP;
END;
/
open: 101
PL/SQL procedure successfully completed.When developing complex SQL statements I often run them standalone in an IDE until I’m satisfied with the result. But when we run this
SELECT count(*) AS open_count
FROM t
WHERE ind = const_boolean.co_true;we get the following error message:
Error starting at line : 1 in command -
SELECT count(*) AS open_count
FROM t
WHERE ind = const_boolean.co_true
Error at Command Line : 3 Column : 14
Error report -
SQL Error: ORA-06553: PLS-221: 'CO_TRUE' is not a procedure or is undefined
06553. 00000 - "PLS-%s: %s"
*Cause:
*Action:We have to change the constant const_boolean.co_true to a literal (1), which is cumbersome and error-prone.
3. Parameterless Functions for Constants
As a workaround, we can create a parameterless function for each constant. Like this:
CREATE OR REPLACE PACKAGE const_boolean AUTHID DEFINER IS
co_true CONSTANT INTEGER := 1;
co_false CONSTANT INTEGER := 0;
FUNCTION true# RETURN INTEGER DETERMINISTIC;
FUNCTION false# RETURN INTEGER DETERMINISTIC;
END const_boolean;
/
CREATE OR REPLACE PACKAGE BODY const_boolean IS
FUNCTION true# RETURN INTEGER DETERMINISTIC IS
BEGIN
RETURN co_true;
END true#;
FUNCTION false# RETURN INTEGER DETERMINISTIC IS
BEGIN
RETURN co_false;
END false#;
END const_boolean;
/Now we can use the function in PL/SQL and SQL like this:
SELECT count(*) AS open_count
FROM t
WHERE ind = const_boolean.true#;
OPEN_COUNT
----------
101So far so good.
4. The Problem
The execution plan of the previous statement looks as follows:
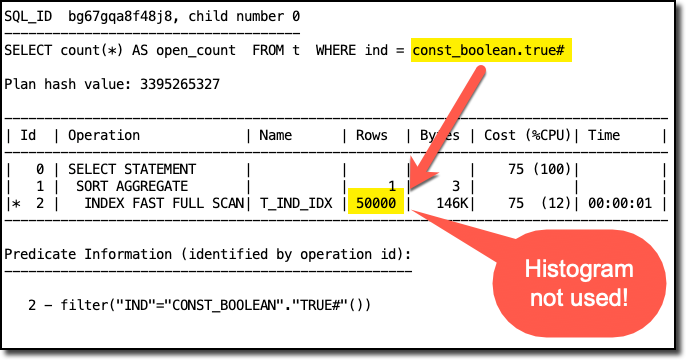
SQL_ID bg67gqa8f48j8, child number 0
-------------------------------------
SELECT count(*) AS open_count FROM t WHERE ind = const_boolean.true#
Plan hash value: 3395265327
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 75 (100)| |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
|* 2 | INDEX FAST FULL SCAN| T_IND_IDX | 50000 | 146K| 75 (12)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("IND"="CONST_BOOLEAN"."TRUE#"())When you look at line 12 you see that the optimizer estimates to process 50000 rows. That’s 50 percent of all rows. This is based on the number of distinct values for column ind and the number of rows in the table t. The optimizer gets this information from here:
SELECT num_rows
FROM user_tables
WHERE table_name = 'T';
NUM_ROWS
----------
100000
SELECT num_distinct
FROM user_tab_columns
WHERE table_name = 'T'
AND column_name = 'IND';
NUM_DISTINCT
------------
2Unfortunately, the histogram for the column ind is ignored. Why? Because the Oracle Database has no idea what the value of const_boolean.true# is. Hence, a histogram is not helpful in finding an execution plan.
An optimal plan would look like this:
SQL_ID bstdc2tsv1qcw, child number 0
-------------------------------------
SELECT count(*) AS open_count FROM t WHERE ind = 1
Plan hash value: 3365671116
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100)| |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
|* 2 | INDEX RANGE SCAN| T_IND_IDX | 101 | 303 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("IND"=1)When you look at line 12, you see that
- an
INDEX RANGE SCANis used and - the number of rows is estimated correctly.
We get this plan when using a literal 1, a bind variable with the bind value 1 (thanks to bind variable peeking) or a constant with value 1 (which is treated as a bind variable in PL/SQL).
The wrong cardinality is a major problem. Because the cardinality is the most important criterion for choosing an optimal access method, join order and join method. Bad cardinality estimates lead to bad execution plans and bad performance. This cannot be ignored, even if in this demo case the resulting performance is still okay.
The problem occurs only if we are accessing columns with significantly skewed data and if these columns have a histogram.
5. Workarounds
We have basically three options to work around the problem:
- For PL/SQL code we can use a constant instead of a parameterless function
(e.g.ind = const_boolean.co_true) - For PL/SQL code or plain SQL like in views, we can use a literal with a comment instead of a parameterless function
(e.g.ind = 1 -- const_boolean.co_true) - For PL/SQL code or plain SQL like in views, we can query the parameterless function in a subquery and force the optimizer to execute it during parse time [added on 2019-12-14]
(e.g.ind IN (SELECT /*+ precompute_subquery */ const_boolean.true# FROM DUAL))
The first option has the drawback, that you have to change the SQL to make it runnable outside of PL/SQL. The second option may lead to inconsistencies due to wrong literal/comment combinations or when changing constant values. The third option requires an IN condition that could be accidentally changed to an equal comparison condition due to the scalar subquery, which would make the undocumented precompute_subquery hint ineffective. [added on 2019-12-14]
Of course, you can continue to use parameterless functions in SQL and PL/SQL and switch to one of the options if there is a problem or if you know that a histogram exists for a certain column. But this is difficult to apply consistently. In fact, it makes maintenance more complicated with a certain performance risk or penalty.
6. Considered Alternatives
I had a look at Associate Statistics (Extensible Optimizer Interface). This does not help, because there is no way to access the related table columns to calculate the impact on the selectivity. The feature is useful if a function gets some parameters to calculate the impact on the selectivity, but without parameters, this is not possible.
I had considered list partitioned tables based on skewed columns instead of using indexes. This works and can make sense to reduce the overhead of an index (especially indexing non-selective values). But the issues regarding parameterless functions are 100 percent the same.
7. Summary
Parameterless functions are a way to use constants in SQL outside of PL/SQL, for example in views. However, they rob the optimizer of the capability to use histograms and therefore find an optimal execution plan.
Actually, we can only work around the problem. The Oracle Database has to provide the solution. Either by allowing to access package global constants in SQL (outside of PL/SQL) or by implementing some kind of peeking for parameterless, deterministic functions.
If you think I missed something important, especially if you think there is a better workaround or even a solution, then please do not hesitate to leave a comment or contact me directly. Thank you.
Updated on 2019-12-14, added a third option under “5. Workarounds” based on a tweet by Jonathan Lewis. Thanks a lot.
4 Comments
(Just for completeness)
I took a look at this back in 2016 to see if SYS_CONTEXT provides any help
https://connor-mcdonald.com/2016/10/20/taking-a-peek-at-sys_context/
Thanks you, Connor, for sharing. Unfortunately, no peeking, no help ;-) .
Morten Braten mentioned https://community.oracle.com/ideas/3320 on Twitter. Accessing global package constants could in fact solve the issue.
Oracle 20 SQL macros will solve this … looking forward to it.
Yes, absolutely. This was also mentioned in the Twitter thread.
But nonetheless I’m interested the hear about what’s planned in to coming releases regarding peeking. I’m looking forward to some news by Nigel Bayliss after his tweets.