

Introduction
I started using SQL Developer in 2013. Back then version 4.0 was the latest and greatest. But the capabilities of the formatter were disappointing. In 2017 Oracle released version 4.2 with a new formatter and has been improving it ever since. Version 19.2 brought us dynamic JavaScript actions within the parse-tree query language Arbori. And now I must admit that I’m really impressed with the formatting capabilities of the latest versions of SQL Developer. Arbori is a hidden gem.
In this blog post, I explain how the formatter works and how the output can be tweaked using two simple SQL queries.
If you only want to activate the coding styles suggested by the Trivadis PL/SQL & SQL Coding Guidelines, install the settings as described here.
How Does Formatting Work?
Formatting is all about adding (or removing) whitespace (line breaks, spaces or tabs) between significant tokens. That sounds easy. Well, it’s not. Because the formatting requirements are very different. Ultimately, it’s all about beautifying the code. And almost every developer has their own views on what makes code look good. Furthermore, it is technically demanding to provide a tool suite that can handle different coding styles via configuration.
The following figure illustrates the formatting process in SQL Developer.
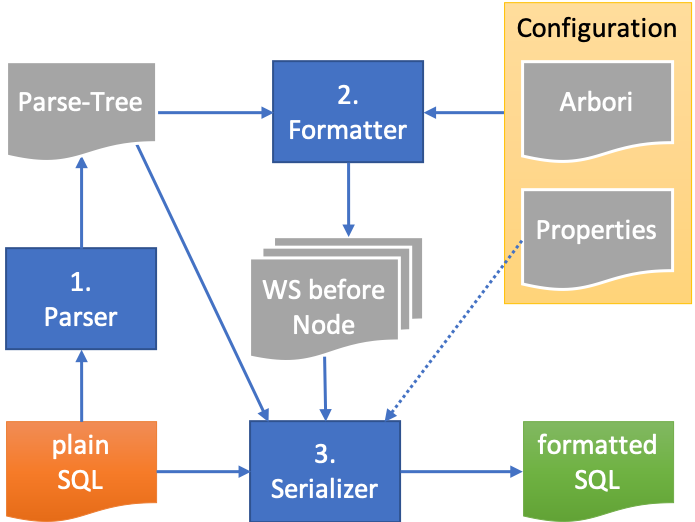
I will explain each step and component in the next chapters.
Please note that these are conceptual components, the actual implementation might look different.
1. Parser
The parser reads the unformatted plain SQL or PL/SQL input and generates a parse-tree. The parse-tree is a hierarchical representation of the significant tokens of the input. In other words, there is neither whitespace nor comments in a parse-tree.
Each node in the parse-tree includes the start and end position within the plain SQL input.
2. Formatter
The formatter needs the parse-tree and the code formatting configuration as input.
SQL Developer stores the configuration in the preferences.
- Under
Code Editor->Format->Advanced Formatfor configuration properties such asLine breaks on comma(after,before,none). - And under
Code Editor->Format->Advanced Format->Custom Formatfor the Arbori program used to handle whitespace.
2.1 Provided Java Callback Functions
The formatter provides the following Java callback functions (in the order how they are expected to be called):
- indentedNodes1
- indentedNodes2
- skipWhiteSpaceBeforeNode
- skipWhiteSpaceAfterNode
- identifiers
- extraBrkBefore
- extraBrkAfter
- brkX2
- rightAlignments
- paddedIdsInScope
- incrementalAlignments
- pairwiseAlignments
- ignoreLineBreaksBeforeNode
- ignoreLineBreaksAfterNode
- dontFormatNode
Each callback functions gets the parameters target (the parse-tree) and tuple (node to be processed). As an Arbori developer you do not have to care about how to populate these parameters. It’s done automatically. target is a global variable and tuple is the result row of an Arbori query. Basically, you only need to query the nodes and call the callback functions. The position in an Arbori program defines the execution order.
These provided Java callback functions have two issues.
First of all, you don’t know what they do. Granted, there are some comments in the provided Arbori program, and also a description in the SQL Developer Users Guide, but this will only give you a rough idea. For example, it leaves you in the dark why `indentedNodes` has two callback functions and both must be called.
Second, you cannot process selected nodes differently. You must write an enhancement request so that the SQL Developer team can provide the necessary callback functionality in a future release. This is cumbersome.
2.2 JavaScript Callback Functions
Thankfully, the SQL Developer team has added a JavaScript callback feature in version 19.2. This allows you to embed callback functions directly into your Arbori program. Now you can really add and remove whitespace wherever you want. The global variable struct gives you access to the instance of the formatter and the configuration properties. As a result, you can manage the whitespace before a position of a node through the methods getNewline and putNewline.
2.3 The Result
Basically, the result of this process is a list of whitespace per position.
3. Serializer
The serializer loops through the leaf nodes of the parse-tree. It retrieves the leading whitespace for a node’s start position and extracts the token text from the pure SQL input using the node’s start and end position. And then the serializer writes the whitespace and the token text to the final result. The formatted SQL.
In fact, the process is actually a bit more complicated. It adds whitespace to mandatory nodes, for instance.
Moreover, the serializer performs some “formatting” without Arbori. For example, it converts the case of identifiers and keywords according to the configuration (properties). Therefore, it is not possible to change the case of a token with an Arbori program. It might be possible by configuring a custom Java formatter class, but that’s another story.
Example Using Provided Java Callback Function
Setup
For this example I use the Advanced Format according the trivadis_advanced_format.xml file. Here’s a screenshot of the configuration settings of my SQL Developer 19.4.0 installation:
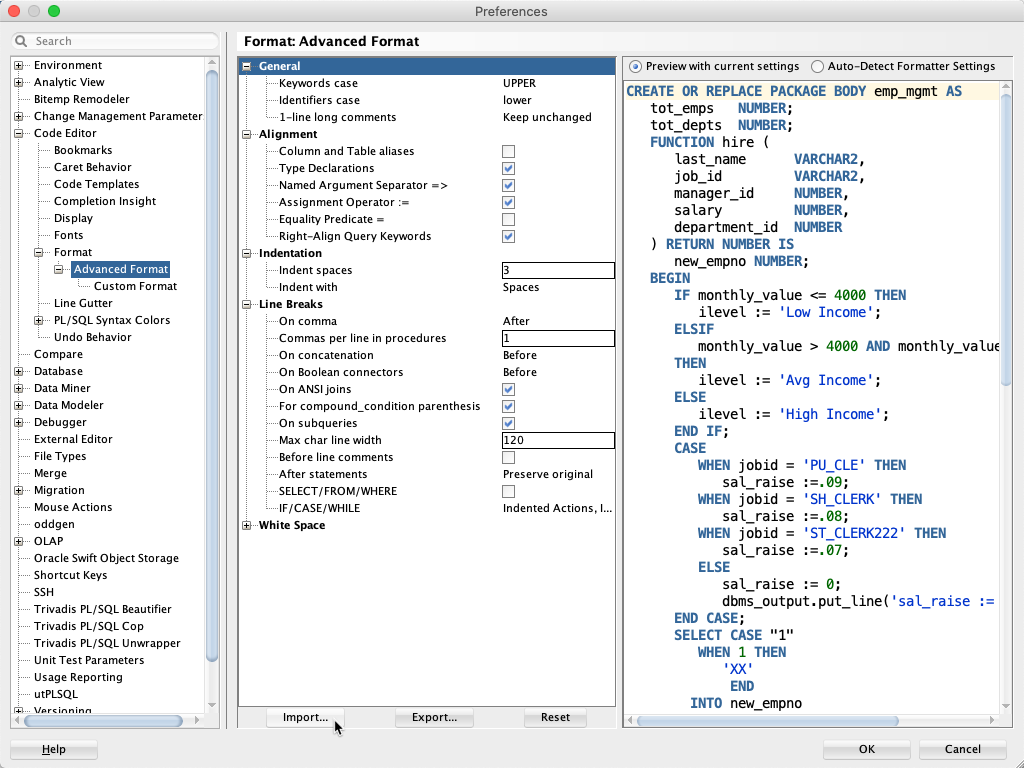
The default is used for the Custom Format.
Default Formatter Result
SELECT e.ename,
e.deptno,
d.dname
FROM dept d
LEFT JOIN emp e
ON d.deptno = e.deptno
ORDER BY e.ename NULLS FIRST;The result looks good, besides the missing indentation on line 6.
Expected Formatter Result
What we expect is this:
SELECT e.ename,
e.deptno,
d.dname
FROM dept d
LEFT JOIN emp e
ON d.deptno = e.deptno
ORDER BY e.ename NULLS FIRST;The ON keyword right-aligned as SELECT, FROM, LEFT and ORDER.
Code Outline
SQL Developer’s code outline is in fact a representation of the full parse-tree. Disable all filters to show all nodes.
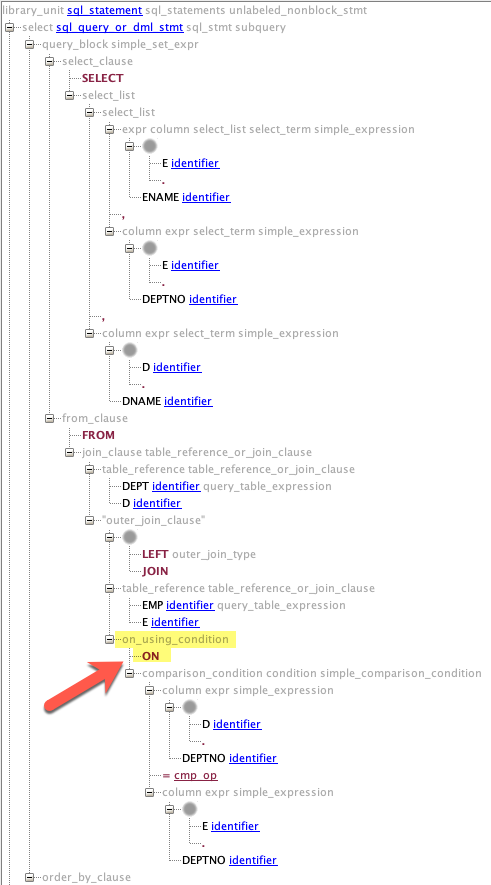
The highlighted information is important for the next step.
Arbori Editor
Type arbori in the search field and press enter as shown below:
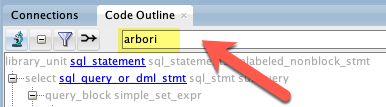
This will open the Arbori Editor. Type the following query in the editor window:
query:
[node) 'ON' & [node^) on_using_condition
;Press Run to display the query result:
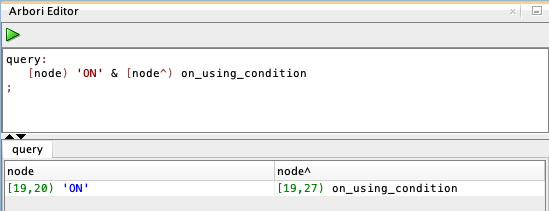
What have we done? We query the parse-tree (outline) for all ON nodes where the parent node is an on_using_condition. A node is represented as [node). And a parent node is represented as [node^). A boolean AND is represented as &. See these links for more information about the Arbori grammar.
Click on the query result cell [19,20) 'ON' to highlight the node in the Code Outline window and the corresponding text in the worksheet. You can do the same with the cell [19,27) on_using_condition.
Change in Arbori Program
Now open the Preferences for Custom Format and search for the query named rightAlignments (it’s usually easier to change the Arbori program in separate editor). It looks like this:
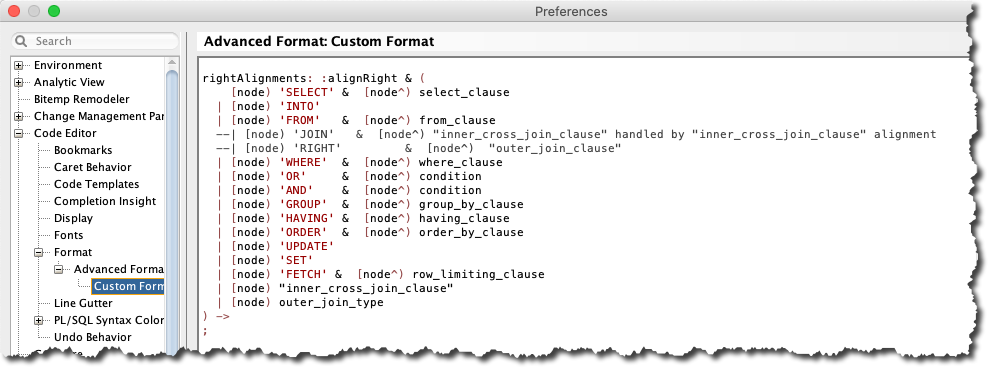
Here some explanation of the query:
- The predicate
:alignRightmeans that the optionRight-Align Query Keywordsmust be checked (true). - We know the boolean AND
&, the current node[node)and the parent node[node^)from the previous query. - The parenthesis
(and)are part of the boolean expression. - The
|is a boolean OR. - The
->at the end means the callback function named as the query (rightAlignments) is called for matching nodes. --is used for single-line comments as in SQL and PL/SQL.
We extend the query by the predicate | [node) 'ON' & [node^) on_using_condition to right-align the ON token.
Here’s the amended query:
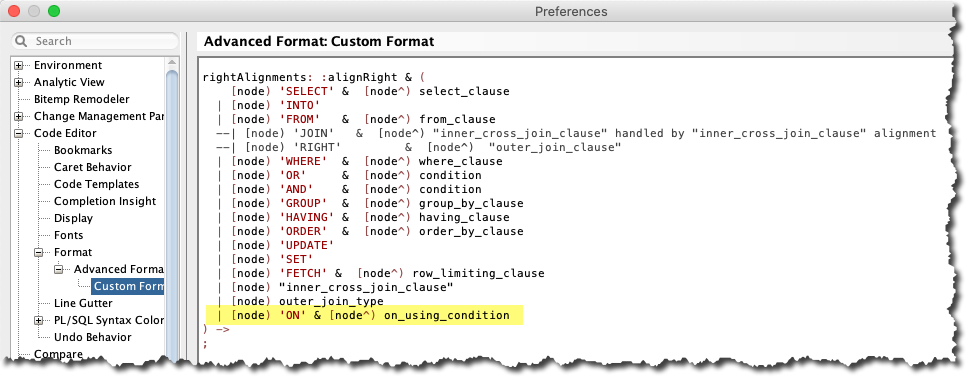
Press OK to save the preferences. Now, the query is formatted correctly.
Example Using JavaScript Callback Function
Default Formatter Result
We use the same setup as for the previous example.
SELECT *
FROM dept d
WHERE EXISTS (
SELECT *
FROM emp e
WHERE e.deptno = d.deptno
AND e.sal > 2900
)
ORDER BY d.deptno;The result does not look too bad. But the indentation feels wrong. Especially when I look at the missing indentation of the ) on line 8. Therefore, I’d like to increase the indentation of the highlighted lines by 7.
Expected Formatter Result
What we expect is this:
SELECT *
FROM dept d
WHERE EXISTS (
SELECT *
FROM emp e
WHERE e.deptno = d.deptno
AND e.sal > 2900
)
ORDER BY d.deptno;Look at the indentation on line 8. ) matches now the indentation of EXISTS (.
Change in Arbori Program
The highlighted code block is already indented. Therefore we cannot use the same mechanism as previously. We want an additional indentation. We can achieve that with an additional query and a JavaScript callback function.
Add the following query at the end of the existing Arbori program in Custom Format of the Preferences:
indentExistsSubqueries:
:breakOnSubqueries & (
[node) subquery & [node-1) '(' & [node+1) ')' & [node^) exists_condition -- the subquery
| [node-1) subquery & [node-2) '(' & [node) ')' & [node^) exists_condition -- close parenthesis
)
-> {
var parentNode = tuple.get("node");
var descendants = parentNode.descendants();
var prevPos = 0
var indentSpaces = struct.options.get("identSpaces") // read preferences for "Indent spaces"
var alignRight = struct.options.get("alignRight") // read preferences for "Right-align query keywords"
var baseIndent
if (alignRight) {
baseIndent = "SELECT ".length; // align to SELECT keyword
} else {
baseIndent = "WHERE ".length; // align to WHERE keyword
}
// result of addIndent varies based on number of "Indent spaces"
var addIndent = ""
for (j = indentSpaces - baseIndent; j < indentSpaces; j++) {
addIndent = addIndent + " ";
}
// addIndent to all nodes with existing indentation
for (i = 0, len = descendants.length; i < len; i++) {
var node = descendants.get(i);
var pos = node.from;
var nodeIndent = struct.getNewline(pos);
if (nodeIndent != null && pos > prevPos) {
struct.putNewline(pos, nodeIndent + addIndent);
prevPos = pos
}
}
}
;Here are some explanation:
- On line 3 and 4 the predicates are defined, for the
subqueryand the closing parenthesis)of anexists_condition. - The JavaScript callback starts on line 6 and ends on line 33.
- The current indentation of a node (position) is read on line 27 and updated on line 29.
Save the preferences to enable the new formatting rules. This is a reduced example. See the PL/SQL & SQL Formatter Settings repository on GitHub for a more complete Arbori program.
Summary
Arbori is the flux capacitor of SQL Developer’s Formatter. Arbori is what makes highly customized code formatting possible.
The Arbori Editor and Code Outline are very useful tools for developing code snippets for an Arbori program. However, it is not easy to get started with Arbori. The information in Vadim Tropashko’s blog is extensive, but it is a challenging and time-consuming read. For me, it was definitely worth it. I hope this blog post helps others to understand Arbori and its potential a bit better.
Any feedback is welcome. Regarding this blog post or the PL/SQL & SQL Formatter Settings on GitHub. Thank you.
34 Comments
I have added your ON clause alignment and extra incremental_alignment conditions, thank you. Will revise and possibly other changes too.
Here are some 20.1 rule enhancements (the release seems to be on hold):
pairwiseAlignments00: predecessor = node^^ & ( [predecessor) function & [node) 'OVER' ); pairwiseAlignments0: predecessor = node^ & ( [predecessor) case_expression & [node) 'END' | [predecessor) else_clause & [node) expr | [predecessor) over_clause & [node) ')' | [predecessor) function & [node) over_clause | [predecessor) function & [node) 'OVER' ); pairwiseAlignments1: predecessor = node-1 & ( [predecessor) group_by_list[5,12) & [node) ',' | [predecessor) order_by_clause[31,38) & [node) ',' | [predecessor) select_list & [node) ',' | [predecessor) cartesian_product & [node) ',' | [predecessor) merge_insert_clause[26,33) & [node) ',' | [predecessor) column & [node) merge_insert_clause[26,33) | [predecessor) "expr_list_def"[16,34) & [node) ',' | [predecessor) "expr_list" & [node) ',' -- leading commas | [predecessor) column & [node) "expr_list_def"[16,34) | [predecessor) merge_update_clause[36,56) & [node) ',' | !:alignRight & [predecessor) condition & [node) AND_OR | [predecessor) expr & [node) compound_expression[25,44) | [predecessor) '>' & [node) expr & [node^) arg | [predecessor) arith_expr & [node) binary_add_op | [predecessor) 'CASE' & [node) searched_case_expression# | [predecessor) searched_case_expression & [node) else_clause | [predecessor) query_partition_clause & [node) order_by_clause ); pairwiseAlignments2: predecessor=node-1-1 & ( [predecessor) select_list & [node) select_term & [node-1) ',' | [predecessor) cartesian_product & [node) table_reference & [node-1) ',' | [predecessor) condition & [node) condition & [node-1) AND_OR | [predecessor) adt_field_list & [node) adt_field & [node-1) ',' | [predecessor) adt_field & [node) adt_field & [node-1) ',' | [predecessor) "expr_list" & [node) expr & [node-1) ',' | [predecessor) expr & [node) expr & [node-1) ',' | [predecessor) expr & [node) expr & [node-1) compound_expression[25,44) | !:breakOnSubqueries & [predecessor) '(' & [node) ')' & [node-1) query_block & ![node^) par_subquery ); pairwiseAlignments30: predecessor=node-1-1-1 & ( [predecessor) 'OVER' & [node) ')' ); pairwiseAlignments3: [predecessor) group_by_list & [predecessor-1) 'BY' & ( [node) ',' | [node) group_by_col ) & predecessor < node ; pairwiseAlignments4: [ob_clause) order_by_clause & predecessor^ = ob_clause & ob_clause < node & [predecessor-1) 'BY' & [predecessor) "ord_by_1desc" & ( [node) ',' | [node) "ord_by_1desc" ); pairwiseAlignments5: [predecessor) prm_spec & [node) prm_spec & predecessor=ancestor-1 & ancestor < node ; pairwiseAlignments6: [predecessor) update_set_clause_expr & [node) update_set_clause_expr & predecessor=ancestor-1 & ancestor < node ; -- https://community.oracle.com/thread/4119671 -- WHEN NOT MATCHED THEN INSERT ( -- crew_seqno, -- inoutdte, -- cardtype, pairwiseAlignments7: [predecessor) column & ![predecessor-1) '=' & [node) column & [node-1) ',' & predecessor=ancestor-1 & ancestor < node ; -- https://community.oracle.com/thread/4202758 /*SET some_long_column_name = source_column3, target_column4 = source_column4, <--align target_column4 = source_column4, target_column5 = source_column5;*/ pairwiseAlignments7_3: [predecessor) column & ![predecessor-1) '=' & [node) column & [node-1) ',' & predecessor=ancestor-3 & ancestor < node ; -- https://community.oracle.com/thread/4119671 --e.g. WHEN MATCHED THEN UPDATE SET tgt.inoutdte = src.inoutdte, -- tgt.cardtype = src.cardtype, -- tgt.tfirstnm = src.tfirstnm; pairwiseAlignments8: [predecessor) column & [node) column & predecessor=node^^-3 ; pairwiseAlignments9: -- https://community.oracle.com/thread/4210584 [predecessor) arg & [node) ',' & [node+1) arg & predecessor=ancestor-1 & ancestor < node ; pairwiseAlignments9_1: -- https://community.oracle.com/message/15540233#15540233 [predecessor) column & [node) ',' & [node+1) column & predecessor=ancestor-3 & ancestor < node ; pairwiseAlignments10: [predecessor) function_call & [node) ')' & predecessor=node^^ ; pairwiseAlignments11: [predecessor) paren_expr_list & [node) arg & predecessor < node ; pairwiseAlignments12: [predecessor) query_partition_clause[12,33) & [node) ',' & predecessor < node ; pairwiseAlignments: pairwiseAlignments00 | pairwiseAlignments0 | pairwiseAlignments1 | pairwiseAlignments2 | pairwiseAlignments30 | pairwiseAlignments3 | pairwiseAlignments4 | pairwiseAlignments5 | pairwiseAlignments6 | pairwiseAlignments7 | pairwiseAlignments7_3 | pairwiseAlignments8 | pairwiseAlignments9 | pairwiseAlignments9_1 | pairwiseAlignments10 | pairwiseAlignments11 | pairwiseAlignments12 -> ;Thank you, Vadim. I appreciate.
As soon as SQL Developer 20.1 is out I’ll merge the changes into the trivadis_custom_format.arbori file on GibHub.
I’ll be more than happy if the differences to the original Arbori file can be reduced. However, I’m not sure if my changes are compatible with/applicable to all combinations of the “Advanced Format” settings (I guess they are not). Basically, I tested only “my favorite” settings with a few variations (comma before/after and number of spaces of indentation).
And talking about testing. That’s something I’ve done manually in SQL Developer. I have to figure out how to automate that.
Vadim helped me via e-mail to understand the formatting process better, showed me some Arbori tricks and how I could run formatting tests outside of SQL Developer (or SQLcl).
Thank you very much, Vadim!
I extended the repository by a test-only Maven project to run formatting tests with JUnit.
Hi Philipp
Thanks for the details about how to configure settings
have question regarding
DECODEis there a way i can configure the setting not to split like below.
i see it is splitting because of
<breaksProcArgs>true</breaksProcArgs>in the format.xmlbut i do want the procedure inputs to be split but not for the decode
desired
Hi Anand,
When I format the code with the default custom settings (Arbori program) in SQL Developer 19.4.0, the result for a complete SQL statement is the following:
SELECT * FROM tgt, src WHERE 1 = 1 OR DECODE( tgt.column1, src.column1, 0, 1 ) = 1;By importing the advanced format trivadis_advanced_format.xml and the custom format trivadis_custom_format.arbori the formatting result looks like this:
SELECT * FROM tgt, src WHERE 1 = 1 OR DECODE(tgt.column1, src.column1, 0, 1) = 1;That’s what you want, right? However, instead of adding an exception for
DECODEI add a line break only if named parameters are used. The next example shows that:SELECT dbms_random.value(1, 100) AS a, dbms_random.value( low => 1, high => 100 ) AS b FROM dual;For that I had to change the following in the Arbori program:
If you really want to change the behavior for
DECODEonly, you could add a fix at the end of the Arbori program that eliminates all whitespaces of the function’s child nodes. Something like this:removeWhitspaceInDecodeFunction: [node) "(x,y,z)" & [node-1) identifier & (?node-1 = 'DECODE') & [node^) function -> { var parentNode = tuple.get("node"); var descendants = parentNode.descendants(); for (i = 1, len = descendants.length; i < len; i++) { var node = descendants.get(i); var pos = node.from; var nodeIndent = struct.getNewline(pos); if (nodeIndent != null) { struct.putNewline(pos, null); } } } ;You can ask questions regarding the formatter behavior in the SQL Developer forum. The SQL Developer team and others are watching this space and are usually very responsive. And if it’s related to the Trivadis PL/SQL and SQL formatter settings, it’s the best to open an issue on GitHub. Thank you.
Thanks alot for your reply and direction on this.
Sure will do that.
Hi Philipp,
Thank you for this fantastic guide to SQL developer formatter! I’m working on SQL/XML queries and unable to get the query formatted properly.
original:
SELECT stg.payload_type, xt_hdr.* FROM stg, XMLTABLE ( '/XML/Header' PASSING xmltype.createxml(stg.xml_payload) COLUMNS source VARCHAR2(50) PATH 'Source', action_type VARCHAR2(50) PATH 'Action_Type', message_type VARCHAR2(40) PATH 'Message_Type', company_id NUMBER PATH 'Company_ID' ) hdr;desired:
SELECT stg.payload_type, xt_hdr.* FROM stg, XMLTABLE ( '/XML/Header' PASSING xmltype.createxml(stg.xml_payload) COLUMNS source VARCHAR2(50) PATH 'Source', action_type VARCHAR2(50) PATH 'Action_Type', message_type VARCHAR2(40) PATH 'Message_Type', company_id NUMBER PATH 'Company_ID' ) hdr;Would you be able to give some directions on how to achieve this in the formatter?
Best Regards,
Venkat
Hi Venkat,
As explained before you need the outline (parse tree) for that. The graphical view shows some node names only as mouse-over text. To produce a parse tree as text you can run this Arbori program in SQLDev 20.2:
print: [node) sql_statements -> { tuple.get("node").printTree(); } ;This result is shown on the console of SQLDev.
[0,55) library_unit sql_statement sql_statements unlabeled_nonblock_stmt [0,54) query_block select simple_set_expr sql_query_or_dml_stmt sql_stmt subquery [0,8) select_clause [0,1) 'SELECT' [1,8) select_list [1,4) column expr expr# select_list select_term simple_expression [1,3) column[4,12) [1,2) identifier [2,3) '.' [3,4) identifier [4,5) ',' [5,8) select_term [5,6) identifier [6,7) '.' [7,8) '*' [8,54) from_clause [8,9) 'FROM' [9,54) cartesian_product [9,10) cartesian_product identifier query_table_expression table_reference table_reference[4,54) table_reference[6,21) table_reference_or_join_clause [10,11) ',' [11,54) table_reference table_reference_or_join_clause [11,53) query_table_expression table_reference[4,54) table_reference[6,21) xmltable [11,12) 'XMLTABLE' [12,13) '(' [13,14) string string_literal [14,52) XMLTABLE_options [14,23) XML_passing_clause [14,15) 'PASSING' [15,23) expr expr# function function_expression user_defined_function [15,18) user_defined_function[4,17) [15,16) identifier [16,17) '.' [17,18) identifier [18,23) "(x,y,z)" [18,19) '(' [19,22) "(x,y,z)"[5,27) "expr_list" column expr expr# simple_expression [19,21) column[4,12) [19,20) identifier [20,21) '.' [21,22) identifier [22,23) ')' [23,52) XMLTABLE_options[19,37) [23,24) 'COLUMNS' [24,31) XML_table_column [24,25) column identifier [25,31) XML_table_column[5,72) [25,29) Oracle_built_in_datatypes XML_table_column[16,49) character_datatypes datatype [25,26) 'VARCHAR2' [26,27) '(' [27,28) digits [28,29) ')' [29,30) 'PATH' [30,31) string string_literal [31,52) XMLTABLE_options[29,36) [31,47) XMLTABLE_options[29,36) [31,39) XMLTABLE_options[29,36) [31,32) ',' [32,39) XML_table_column [32,33) column identifier [33,39) XML_table_column[5,72) [33,37) Oracle_built_in_datatypes XML_table_column[16,49) character_datatypes datatype [33,34) 'VARCHAR2' [34,35) '(' [35,36) digits [36,37) ')' [37,38) 'PATH' [38,39) string string_literal [39,40) ',' [40,47) XML_table_column [40,41) column identifier [41,47) XML_table_column[5,72) [41,45) Oracle_built_in_datatypes XML_table_column[16,49) character_datatypes datatype [41,42) 'VARCHAR2' [42,43) '(' [43,44) digits [44,45) ')' [45,46) 'PATH' [46,47) string string_literal [47,48) ',' [48,52) XML_table_column [48,49) column identifier [49,52) XML_table_column[5,72) [49,50) 'NUMBER' Oracle_built_in_datatypes XML_table_column[16,49) datatype number_datatypes [50,51) 'PATH' [51,52) string string_literal [52,53) ')' [53,54) identifier [54,55) ';'Now you have all information you need.
In the first step we add some additional line breaks. For that we add the following code to the
_extraBrkBeforeQuery of the formatter’s Arbori program:Now, when you format your code, the result looks like this:
SELECT stg.payload_type, xt_hdr.* FROM stg, XMLTABLE ( '/XML/Header' PASSING xmltype.createxml(stg.xml_payload) COLUMNS source VARCHAR2(50) PATH 'Source', action_type VARCHAR2(50) PATH 'Action_Type', message_type VARCHAR2(40) PATH 'Message_Type', company_id NUMBER PATH 'Company_ID' ) hdr;Much better, right?
The second step is to align
PASSINGandCOLUMNS. The right callback for this operation ispairwiseAlignmentspairwiseAlignmentXmlTable: [predecessor) string & [node) 'PASSING' & predecessor=node^^-1 | [predecessor) XML_passing_clause & [node) XMLTABLE_options[19,37) & predecessor=node-1 | [predecessor) 'XMLTABLE' & [node) ')' & predecessor=node-4 ; pairwiseAlignmentXmlTableColumn: [predecessor) XML_table_column & [ancestor) XMLTABLE_options[19,37) & [node) XML_table_column & [node-1) ',' & ancestor<predecessor & ancestor<node & ancestor=predecessor^ ; pairwiseAlignments: pairwiseAlignments1 | pairwiseAlignments2 | pairwiseAlignments3 | pairwiseAlignments4 | pairwiseAlignments5 | pairwiseAlignments6 | pairwiseAlignments7 | pairwiseAlignments7_3 | pairwiseAlignments8 | pairwiseAlignments9 | pairwiseAlignmentXmlTable | pairwiseAlignmentXmlTableColumn -> ;I added the highlighted lines.
After this change the formatting result looks like this.
SELECT stg.payload_type, xt_hdr.* FROM stg, XMLTABLE ( '/XML/Header' PASSING xmltype.createxml(stg.xml_payload) COLUMNS source VARCHAR2(50) PATH 'Source', action_type VARCHAR2(50) PATH 'Action_Type', message_type VARCHAR2(40) PATH 'Message_Type', company_id NUMBER PATH 'Company_ID' ) hdr;Looks exactly like your desired result.
Cheers,
Philipp
Hi Philipp,
Kudos to your efforts !! Thank you once again for your detailed explanations. Worked like a charm.
Best Regards,
Venkat
Dear Philipp,
I’m trying to follow your post in SQL Developer 20.2 and can’t get printTree() to return the full parse tree.
ScreenShotOfMyWork
My sql statement
Code run in Arbori worksheet
print: [node) sql_statements -> { tuple.get("node").printTree(); } ;Output on the print tab
[0,5) library_unit sql_statement sql_statements unlabeled_nonblock_stmt
Thanks for taking the time to help,
-jeff
Hi Jeff,
By default SQL Developer is started without console window. Therefore the result of
printTree()is not visible. Based on your screenshot I see that you are using Windows. Under Windows you can start SQL Developer with a console window by choosing the “sqldeveloper64.exe” in the “sqldeveloper\bin” directory as shown in the following screenshot:And when you repeat your experiment than you should get something similar like this:
Cheers,
Philipp
Success! I’m able to see the console now.
Thanks much,
-jeff
Hello Phillip,
I have the following arbori file, which prevents breaks on arguments of functions like nvl, decode, trunc, but keeps the break on custom procedures/functions.
The problem that I have is that it puts the breaks in number(38,0) declaration, and I would like to prevent that.
I would like to have it like in the right example, can you help me?
Thank you very much. Below I paste the arbori file. (removed by Philipp Salvisberg)
Your Arbori program has almost 900 lines of code and has syntax errors. This is not the place to discuss a complete Arbori program. You cannot expect that I fix your syntax errors first and then try to figure out what you changed from the default configuration and what you want to do.
If you use the default Arbori program there is no line break in
number(38,0). In the Trivadis PL/SQL & SQL formatter settings there will be no line breaks for function calls with less than 5 parameters. This is solved here. There is also an open enhancement request to add line breaks only if the parameters do not fit on a single line. I plan to implement that when SQLDev 20.4 becomes available.If you have question regarding this blog post feel free to ask them here. If you have questions regarding the Trivadis PL/SQL & SQL formatter settings then please open a GitHub issue. And if you have questions regarding Arbori in general or how to solve a specific formatting problem, then I suggest to open a question in the SQL Developer forum.
Thanks.
I found this blog a few months ago as SQL Developer formatting has always been a major irritant:-) I’m a lazy ex-DBA doing some development every now and then and I just want to hit a button and have readable code. Thanks, great interesting stuff!
I’ve worked on Oracle Retail implementation projects (including an 8 year stint in consulting for Oracle) since the late nineties and they have a set of SQL formatting standards for Oracle Retail inherited from the company that wrote the product (Retek). Does Oracle have a standard set of formatting rules for the Oracle group as a whole? I fully realise that Oracle is more like a many headed hydra dragon (clients often say ‘Oracle says…’ but it ain’t so) rather than something with a singular head, and often these heads eat each other:-) but it would be interesting to have a standard Oracle setup in the product.
You’re welcome.
SQL Developer comes with default formatter settings. You can easily change some (advanced) settings such as the default indentation etc. If you are not happy with the result you technically can configure the formatter to produce the wanted result. The problem is, that it takes time. In fact, a lot of time since the combined grammar of SQLcl, SQL and PL/SQL is huge.
Thanks, I’ve been hacking around with the settings quite a bit, banging my head, cursing, etc, have got something going based on your earlier blog that works for me. My interest was whether Oracle themselves have an internal standard for their own development but I suspect each development group does their own thing.
I don’t know. But I can imagine that your assumption is correct.
Hi Philipp,
do you know if it’s possible in SQL Developer to protect source code sections from being formatted?
For instance, “PL/SQL Developer” uses predefined comments for this:
— noFormat Start
PROCEDURE do_not_change_this IS BEGIN NULL; END;
— noFormat End
If there is no given option in SQL Developer, I might take a deeper look into Arbori – if you think this could be achieved somehow.
Thanks,
Andreas
SQL Developer does not support this out of the box. However, the Trivadis PL/SQL & SQL Formatter Settings do. The PL/SQL Developer and Eclipse syntax work. See https://github.com/Trivadis/plsql-formatter-settings#disable-formatter.
[…] this blog post I explained how the formatter in SQL Developer works and outlined how you can change the formatter […]
[…] next figure illustrates the highlighting process in SQL Developer. The similarities to the formatting process are no […]
Hi,
We have just switched to Sql Developer and I have never used arbori and cant get my head fully around it. I would like to use it to do the following.
Whenever I format code in sql developer Iwould like to append (or update) the first line with the following:
/* Formatted on YYYY-MM-DD HH24:MI:SS */
Maybe you can hint me on how to implement this?
BR
The formatter based on Arbori manages whitespace before nodes. You want to add/modify a comment. That’s not formatting anymore. However, the tool-suite allows to access the underlying code. The global variable
targetcontainsinput.inputcontains the complete source code. The formatter will update this field. So you could add some processing to manipulate this field. From this point on it has basically nothing to do with Arbori nor formatting.I know that the formatter in TOAD allows to generate such a comment. TOAD has also the ability to disable this comment generation, which is a good thing IMO. You do not want to create a new version of the source code where the only change is the timestamp when the code was last formatted.
For questions that are not related to this blog post I kindly ask you to seek help in the Oracle SQL Developer forum. Thank you.
Thank you for your quick answer and apologies if my question is not related to this.
However I found the following in the arbori file which comes included with the Sql developer 22 release.
timestamp: runOnce & false -> { var date = new java.util.Date(); var formatted = "/* Formatted by SqlDev on "; var index = target.input.indexOf(formatted); if( index != 0 ) struct.putNewline(0, formatted+date+" */\n"); else { var timestampEnd = target.input.indexOf(" */"); target.input = formatted+date+target.input.substring(timestampEnd); } }This is exactly what you mention and it is thanks to your post that I found it.
I am not sure what runOnce & false is. Could be some Sql developer settings but not that I could find. I tried to just change the condition to true but to no avail.
If you could shed some light on it I would appreciate it. If not then please just ignore it.
BR
Yes, the
timestamprule is part of SQL Developers’s default Arbori program (in newer versions only). Just remove& falseto activiate it. it will add/replace the formatter comment on the first line (it works, I’ve tested it).The
runOncecondition is defined instd.arbori. It looks like this:This condition is used to ensure an Arbori rule is executed exactly once.
Hi,
I was wondering if doing something like that was possible :
INSERT INTO test (col1, col2, col3, col4, col5, col6) VALUES (val1, val2, val3, val4, val5, val6)Thanks,
VM
With my settings the formatter result will look like this:
If this is not what you expect, you can of course change it by amending the Arbori code. Basically (almost) everything possible if you have enough time and money.
Try out the latest formatter settings in this GitHub repo. If you have suggestions to improve the formatter result then you can open an issue provide your settings, your input, your actual output and your expected output. If it is a reasonable request and something others may benefit as well, than there is a chance it will be considered in a future version.
Seems the format doesn’t work here i’ll explain :
I want to do a line break after every 3 value of an INSERT INTO statement,
same thing for the VALUES statement.
keyword “VALUES” has to be right aligned with the table name of the INSER INTO (in my example with test)
The statement in you previous post was formatted like this:
INSERT INTO test (col1, col2, col3, col4, col5, col6) VALUES (val1, val2, val3, val4, val5, val6)IMO that’s a rather uncommon formatting style. The rules are not clear to me (e.g. the indentation and the alignment). However, limiting columns to 3 per line is doable with Arbori and JavaScript. I can’t offer you a solution in the comments to this blog post, but you can study these links provided in the GitHub repo mentioned above to produced the expected result yourself.
Here is the correct format i would like to achieve :
INSERT INTO ma_table (col1, col2, col3, col4, col5, col6, col7, col8, col9) VALUES (val1, val2, val3, val4, val5, val6, val7, val8, val9);Yes, that’s doable
Hello Philipp, to be able to do the line break every 3 element i have done this,
However i’m stuck when it comes to indent, i want to align to the first element of the INSERT INTO statement, in my exemple aligne to “col1”.
Can you help me further ?
Much appreciated
VM
prelude: runOnce -> { var count = 1; var accumulatedString = ""; var accumulatedSet = []; }; insertIntoBrk: [stmt) insert_into_clause & [node) column & [node) identifier & stmt { var node = tuple.get("node"); var content = target.src[node.from].content; for( var i = 0; i<content.length; i++ ) { if(count % 3 == 0 ) { var nodeIndent = '\n'; struct.putNewline(node.to + 1, nodeIndent); break; } } count++; };While you can do what you want, it is not that simple. Besides standalone insert statements you have to deal with existing indentations produced by other rules that where applied for PL/SQL blocks, if statements, case statements, loops, etc.
This blog post is a basic introduction of the formatter in SQL Developer. It’s the wrong place to deal with specific formatter/Arbori questions and issues. The right place for these kind of questions is the Oracle forum for SQL Developer. I kindly ask you to seek help there. Thank you.