


I recently had a few discussions regarding the Smart Database Paradigm (SmartDB) with long-standing customers, new customers, partners, competitors and colleagues. Some people think that using APEX and PL/SQL in their database application is SmartDB. But it is not that simple. Bryn Llewelyn defined the term “Smart Database Paradigm” (SmartDB) in his talk Guarding your data behind a hard shell PL/SQL API. Based on his definition a SmartDB application must have the following five properties:
- The connect user does not own database objects
- The connect user can execute PL/SQL API units only
- PL/SQL API units handle transactions
- SQL statements are written by human hand
- SQL statements exploit the full power of set-based SQL
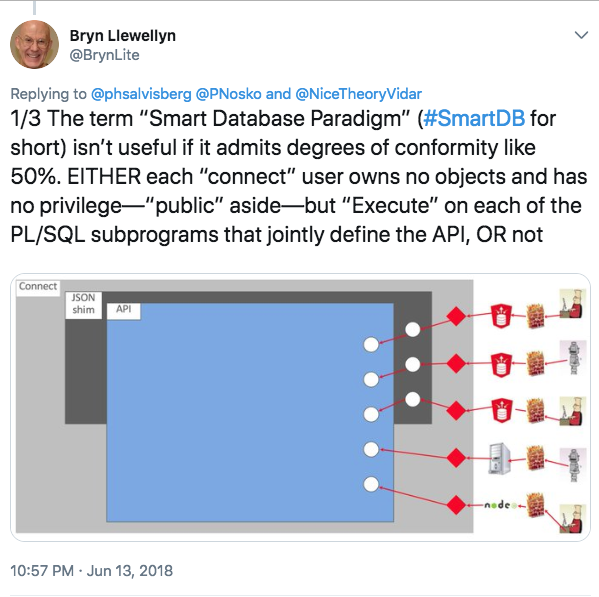
These five properties are not a set of recommendations. They are the bare minimum. Either your application has these properties or not. It’s binary. There is (almost) no room for interpretation. Here’s an excerpt of a longer Twitter thread, making my and especially Bryn Llewelyn’s view a bit clearer.

In this blog post I show how to check the compliance with the first three SmartDB properties by querying the Oracle data dictionary. The remaining two SmartDB properties have to be evaluated manually using reviews. The goal is to show that some of these properties are easily not followed (for good reasons) and that makes your database-centric application something else than SmartDB (but not necessarily a curate’s egg).
In How to Prove That Your SmartDB App Is Secure I’ve crafted a good, a bad and an ugly demo application. I installed these applications using this script in my Oracle Database 18c instance.
The anonymous PL/SQL block and the SQL queries in this blog post require DBA privileges. The required minimum database version is mentioned in the title of the code block, e.g. (>=9.2), (>=12.1) or (>=12.2).
Now let’s look at the five SmartDB properties.
1. The connect user does not own database objects
The connect user is used by application components outside of the database to interact with the database. It is configured for example in the connection pool of the middle-tier application.
The connect user must access only the APIs of the underlying database applications and therefore does not need own database objects.
Checking the compliance of this property is simple.
SELECT username
FROM dba_users
WHERE username NOT IN (
SELECT owner
FROM dba_objects
)
ORDER BY username;USERNAME
------------------------
ANONYMOUS
APEX_INSTANCE_ADMIN_USER
APEX_PUBLIC_USER
APEX_REST_PUBLIC_USER
DIP
GGSYS
GSMCATUSER
GSMUSER
MDDATA
ORDS_PUBLIC_USER
SYS$UMF
SYSBACKUP
SYSDG
SYSKM
SYSRAC
THE_BAD_USER
THE_GOOD_USER
THE_UGLY_USER
XS$NULL
19 rows selected.If you are using a connect user that is not listed as a result, then your application is not SmartDB.
The result contains also users that do not have the CREATE SESSION privilege and therefore cannot be used as connect users. The queries to check SmartDB properties 2 and 3 will address this issue.
2. The connect user can execute PL/SQL API units only
Database views and tables are guarded behind a hard shell PL/SQL API. Only the following database objects may be part of the API:
- Packages
- Types
- Functions
- Procedures
So we just have to check if the connect user has access to objects with the predicate object_type NOT IN ('PACKAGE', 'TYPE', 'FUNCTION', 'PROCEDURE'), right? Yes, but the result would not be helpful. Why? Because every user with just the CREATE SESSION privilege has access to some thousand tables and views via the PUBLIC role. For example DUAL, ALL_VIEWS or NLS_SESSION_PARAMETERS. Strictly speaking, it is not possible to create an Oracle user that can execute PL/SQL units only. Some might argue that this alone makes SmartDB applications a fantasy. However, I’m not in that camp. I think we just have to focus on our own objects and exclude all Oracle-maintained users along with some common utility users from the analysis.
Furthermore, the connect user should only have the CONNECT role (no more and no less). This way we ensure/know that no access is granted to internal objects via ANY privileges.
For this check, we can reuse the query for rule 1 from my previous blog post How to Prove That Your SmartDB App Is Secure.
WITH
-- roles as recursive structure
role_base AS (
-- roles without parent (=roots)
SELECT r.role, NULL AS parent_role
FROM dba_roles r
WHERE r.role NOT IN (
SELECT p.granted_role
FROM role_role_privs p
)
UNION ALL
-- roles with parent (=children)
SELECT granted_role AS role, role AS parent_role
FROM role_role_privs
),
-- roles tree, calculate role_path for every hierarchy level
role_tree AS (
SELECT role,
parent_role,
sys_connect_by_path(ROLE, '/') AS role_path
FROM role_base
CONNECT BY PRIOR role = parent_role
),
-- roles graph, child added to all ancestors including self
-- allows simple join to parent_role to find all descendants
role_graph AS (
SELECT DISTINCT
role,
regexp_substr(role_path, '(/)(\w+)', 1, 1, 'i', 2) AS parent_role
FROM role_tree
),
-- application users in scope of the analysis
-- other users are treated as if they were not installed
app_user AS (
SELECT username
FROM dba_users
WHERE oracle_maintained = 'N' -- SYS, SYSTEM, SYSAUX, ...
AND username NOT IN ('FTLDB', 'PLSCOPE', 'UT3')
),
-- user system privileges
sys_priv AS (
-- system privileges granted directly to users
SELECT u.username, p.privilege
FROM dba_sys_privs p
JOIN app_user u ON u.username = p.grantee
UNION
-- system privileges granted directly to PUBLIC
SELECT u.username, p.privilege
FROM dba_sys_privs p
CROSS JOIN app_user u
WHERE p.grantee = 'PUBLIC'
AND p.privilege NOT IN (
SELECT r.role
FROM dba_roles r
)
UNION
-- system privileges granted to users via roles
SELECT u.username, p.privilege
FROM dba_role_privs r
JOIN app_user u ON u.username = r.grantee
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_sys_privs p ON p.grantee = g.role
UNION
-- system privileges granted to PUBLIC via roles
SELECT u.username, p.privilege
FROM dba_role_privs r
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_sys_privs p ON p.grantee = g.role
CROSS JOIN app_user u
WHERE r.grantee = 'PUBLIC'
),
-- user object privileges
obj_priv AS (
-- objects granted directly to users
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_tab_privs p
JOIN app_user u ON u.username = p.grantee
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
UNION
-- objects granted to users via roles
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_role_privs r
JOIN app_user u ON u.username = r.grantee
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_tab_privs p ON p.grantee = g.role
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
-- objects granted to PUBLIC
UNION
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_tab_privs p
CROSS JOIN app_user u
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
AND p.grantee = 'PUBLIC'
),
-- issues if user is configured in the connection pool of a middle tier
issues AS (
-- privileges not part of CONNECT role
SELECT username,
'SYS' AS owner,
'PRIVILEGE' AS object_type,
privilege AS object_name,
'Privilege is not part of the CONNECT role' AS issue
FROM sys_priv
WHERE privilege NOT IN ('CREATE SESSION', 'SET CONTAINER')
-- access to non PL/SQL units
UNION ALL
SELECT username,
owner,
object_type,
object_name,
'Access to non-PL/SQL unit'
FROM obj_priv
WHERE object_type NOT IN ('PACKAGE', 'TYPE', 'FUNCTION', 'PROCEDURE')
-- own objects
UNION ALL
SELECT u.username,
o.owner,
o.object_type,
o.object_name,
'Connect user must not own any object'
FROM app_user u
JOIN dba_objects o ON o.owner = u.username
-- missing CREATE SESSION privilege
UNION ALL
SELECT u.username,
'SYS',
'PRIVILEGE',
'CREATE SESSION',
'Privilege is missing, but required'
FROM app_user u
WHERE u.username NOT IN (
SELECT username
FROM sys_priv
WHERE privilege = 'CREATE SESSION'
)
),
-- aggregate issues per user
issue_aggr AS (
SELECT u.username, COUNT(i.username) issue_count
FROM app_user u
LEFT JOIN issues i ON i.username = u.username
GROUP BY u.username
),
-- user summary (calculate is_smartdb_property_2_met)
summary AS (
SELECT username,
CASE
WHEN issue_count = 0 THEN
'YES'
ELSE
'NO'
END AS is_smartdb_property_2_met,
issue_count
FROM issue_aggr
ORDER BY is_smartdb_property_2_met DESC, username
)
-- main
SELECT *
FROM summary
WHERE issue_count = 0;USERNAME IS_SMARTDB_PROPERTY_2_MET ISSUE_COUNT
------------------------ ------------------------- -----------
APEX_REST_PUBLIC_USER YES 0
THE_BAD_USER YES 0
THE_GOOD_USER YES 0If you are using a connect user that is not listed as a result, then your application is not SmartDB.
In this case, the APEX_REST_PUBLIC_USER is a false positive. The named subquery app_user excludes the APEX_180100 user which grants various views and sequences to PUBLIC. Hence APEX 18.1 is not a SmartDB application.
3. PL/SQL API units handle transactions
A SmartDB application holds the complete business logic in the database. A PL/SQL API call handles a transaction completely. The API must not contain units for partial transaction work. Such units may exist, but must not be part of the PL/SQL API exposed to the connect user.
For write operations a COMMIT is called on success and a ROLLBACK is called on failure at the end of the operation.
For read operations, the PL/SQL API is responsible for the read consistency.
Distributed transactions are supported via database links only. Other data sources cannot participate in the same database transaction. If this is a mandatory requirement, then SmartDB is the wrong approach. However, Oracle AQ can be a good alternative to propagate data consistently in upstream or downstream transactions.
To check if an application has this SmartDB property, we have to do something like this:
- Find all PL/SQL API units (as we’ve done for the SmartDB property 2).
- Produce a call tree for PL/SQL API units. On the object level, this could be achieved by querying
DBA_DEPENDENCIES. For a more accurate result on the sub-object level, PL/Scope could be used by queryingDBA_IDENTIFIERS. - Find
INSERT,UPDATE,DELETE,MERGE,COMMITandROLLBACKstatements in PL/SQL units. Static statements can be found via PL/Scope in theDBA_STATEMENTSview. But executions in dynamic statements are a challenge, since the DML may be stored outside of the PL/SQL unit (e.g. in tables). It’s virtually impossible to get a complete result using static code analysis. - Bring these results together and check if DML statements are followed by a transaction control statement. This is another challenge. Without a parser (and some semantic analysis) it is not possible to find out if a statement is really executed (e.g. PL/Scope does not provide information about control structures).
For this blog post, we use a naïve static code analysis approach. We analyze the object level and consider static SQL statements only. Furthermore, we assume that DML statements (INSERT, UPDATE, DELETE, MERGE) and transaction control statements (COMMIT, ROLLBACK) found in the call hierarchy are all executed and the transaction control statement is at the very end.
As long as the transaction control statements are not executed as dynamic SQL the result should be good enough. This means if the query produces no result for an application, then this is for sure not a SmartDB application, but if a result is produced, then this does not guarantee that the application is really following the rules and issuing a COMMIT or a ROLLBACK at the end of a write transaction.
SET SERVEROUTPUT ON SIZE UNLIMITED
DECLARE
PROCEDURE exec_sql (in_sql_stmt IN VARCHAR2) IS
BEGIN
dbms_output.put_line('executing: ' || in_sql_stmt);
EXECUTE IMMEDIATE in_sql_stmt;
END exec_sql;
--
PROCEDURE enable_plscope IS
BEGIN
exec_sql(q'[ALTER SESSION SET plscope_settings='IDENTIFIERS:ALL, STATEMENTS:ALL']');
END enable_plscope;
--
PROCEDURE compile_private_synonyms(in_user IN VARCHAR2) IS
BEGIN
<<synonyms>>
FOR r IN (
SELECT synonym_name
FROM dba_synonyms
WHERE owner = in_user
) LOOP
exec_sql('ALTER SYNONYM "' || in_user || '"."' || r.synonym_name || '" COMPILE');
END LOOP synonyms;
END compile_private_synonyms;
--
PROCEDURE compile_public_synonyms(in_user IN VARCHAR2) IS
BEGIN
FOR r IN (
SELECT synonym_name
FROM dba_synonyms
WHERE owner = 'PUBLIC'
AND table_owner = in_user
) LOOP
exec_sql('ALTER PUBLIC SYNONYM "' || r.synonym_name || '" COMPILE');
END LOOP public_synonyms;
END compile_public_synonyms;
--
PROCEDURE compile_types(in_user IN VARCHAR2) IS
e_has_table_deps EXCEPTION;
e_is_not_udt EXCEPTION;
e_compile_error EXCEPTION;
PRAGMA exception_init(e_has_table_deps, -2311);
PRAGMA exception_init(e_is_not_udt, -22307);
PRAGMA exception_init(e_compile_error, -24344);
BEGIN
<<types>>
FOR r IN (
SELECT o.object_type, o.object_name, count(d.name) AS priority
FROM dba_objects o
LEFT JOIN dba_dependencies d
ON d.owner = o.owner
AND d.type = o.object_type
AND d.name = o.object_name
WHERE o.owner = in_user
AND o.object_type in ('TYPE', 'TYPE BODY')
GROUP BY o.object_type, o.object_name
ORDER BY priority
) LOOP
<<compile_type>>
BEGIN
IF r.object_type = 'TYPE' THEN
exec_sql('ALTER TYPE "' || in_user || '"."' || r.object_name || '" COMPILE');
ELSE
exec_sql('ALTER TYPE "' || in_user || '"."' || r.object_name || '" COMPILE BODY');
END IF;
EXCEPTION
WHEN e_has_table_deps OR e_is_not_udt OR e_compile_error THEN
NULL;
END compile_type;
END LOOP types;
END compile_types;
--
PROCEDURE compile_schema(in_user IN VARCHAR2) IS
BEGIN
-- synonyms and types are not covered by dbms_utility.compile_schema
compile_private_synonyms(in_user);
compile_public_synonyms(in_user);
compile_types(in_user);
dbms_utility.compile_schema(
schema => in_user,
compile_all => TRUE,
reuse_settings => FALSE
);
END compile_schema;
BEGIN
enable_plscope;
<<app_user>>
FOR r IN (
SELECT username
FROM dba_users
WHERE oracle_maintained = 'N'
AND username NOT IN ('FTLDB', 'PLSCOPE', 'UT3')
) LOOP
compile_schema(r.username);
END LOOP app_user;
END;
/WITH
-- calculate object dependencies recursively
-- using PL/SQL to handle cycles (expected on object level)
-- SQL variant using NOCYCLE did not work (runs forever)
FUNCTION get_dep (
in_xml IN XMLTYPE
) RETURN XMLTYPE IS
l_deps sys.ora_mining_varchar2_nt;
l_result XMLTYPE := XMLTYPE('<xml/>');
l_element XMLTYPE;
--
PROCEDURE add_child(
io_deps IN OUT sys.ora_mining_varchar2_nt,
in_owner IN VARCHAR2,
in_type IN VARCHAR2,
in_name IN VARCHAR2,
in_has_dml IN INTEGER,
in_has_transaction IN INTEGER
) IS
BEGIN
io_deps.extend;
io_deps(io_deps.count) := in_owner || '.' || in_type || '.' || in_name
|| '.' || in_has_dml || '.' || in_has_transaction;
END add_child;
--
FUNCTION exists_child(
in_deps IN sys.ora_mining_varchar2_nt,
in_owner IN VARCHAR2,
in_type IN VARCHAR2,
in_name IN VARCHAR2,
in_has_dml IN INTEGER,
in_has_transaction IN INTEGER
) RETURN BOOLEAN is
l_found INTEGER;
BEGIN
SELECT COUNT(*)
INTO l_found
FROM table(in_deps)
WHERE column_value = in_owner || '.' || in_type || '.' || in_name
|| '.' || in_has_dml || '.' || in_has_transaction
AND rownum = 1;
RETURN l_found > 0;
END exists_child;
--
PROCEDURE add_children(
io_deps IN OUT sys.ora_mining_varchar2_nt,
in_xml IN XMLTYPE,
in_owner IN VARCHAR2,
in_type IN VARCHAR2,
in_name IN VARCHAR2
) IS
BEGIN
FOR r IN (
SELECT owner, type, name, has_dml, has_transaction
FROM XMLTABLE(
'xml/row/value/dependency[../../key/owner=$owner and ../../key/type=$type and ../../key/name=$name]'
PASSING in_xml, in_owner AS "owner", in_type AS "type", in_name AS "name"
COLUMNS owner VARCHAR2(128) PATH 'referenced_owner',
type VARCHAR2(128) PATH 'referenced_type',
name VARCHAR2(128) PATH 'referenced_name',
has_dml INTEGER PATH 'referenced_has_dml',
has_transaction INTEGER PATH 'referenced_has_transaction'
)
) LOOP
IF NOT exists_child(io_deps, r.owner, r.type, r.name, r.has_dml, r.has_transaction) THEN
add_child(io_deps, r.owner, r.type, r.name, r.has_dml, r.has_transaction);
add_children(io_deps, in_xml, r.owner, r.type, r.name);
END IF;
END LOOP;
END add_children;
---
FUNCTION get_fragment(
in_deps IN sys.ora_mining_varchar2_nt,
in_owner IN VARCHAR2,
in_type IN VARCHAR2,
in_name IN VARCHAR2
) RETURN XMLTYPE IS
l_xml XMLTYPE;
BEGIN
SELECT XMLELEMENT("xml",
XMLAGG(
XMLELEMENT("row",
XMLELEMENT("owner", in_owner),
XMLELEMENT("type", in_type),
XMLELEMENT("name", in_name),
XMLELEMENT("referenced_owner", regexp_substr(column_value, '[^\.]+', 1, 1)),
XMLELEMENT("referenced_type", regexp_substr(column_value, '[^\.]+', 1, 2)),
XMLELEMENT("referenced_name", regexp_substr(column_value, '[^\.]+', 1, 3)),
XMLELEMENT("referenced_has_dml", regexp_substr(column_value, '[^\.]+', 1, 4)),
XMLELEMENT("referenced_has_transaction", regexp_substr(column_value, '[^\.]+', 1, 5))
)
)
)
INTO l_xml
FROM table(in_deps);
RETURN l_xml;
END get_fragment;
---
PROCEDURE add_to_result(
io_result IN OUT XMLTYPE,
in_fragment IN XMLTYPE
) IS
BEGIN
SELECT xmlquery('
copy $i := $p1 modify
(
for $j in $i/xml
return insert node $p2 into $j
)
return $i'
PASSING io_result AS "p1", in_fragment.extract('/xml/row') AS "p2"
RETURNING CONTENT
)
INTO io_result
FROM dual;
END add_to_result;
BEGIN
FOR r IN (
SELECT owner, type, name
FROM XMLTABLE (
'/xml/row/key'
PASSING in_xml
COLUMNS owner VARCHAR2(128) PATH 'owner',
type VARCHAR2(128) PATH 'type',
name VARCHAR2(128) PATH 'name'
)
)
LOOP
l_deps := sys.ora_mining_varchar2_nt();
add_children(l_deps, in_xml, r.owner, r.type, r.name);
add_to_result(l_result, get_fragment(l_deps, r.owner, r.type, r.name));
END LOOP;
RETURN l_result;
END get_dep;
-- application users in scope of the analysis
-- other users are treated as if they were not installed
app_user AS (
SELECT username
FROM dba_users
WHERE oracle_maintained = 'N' -- SYS, SYSTEM, SYSAUX, ...
AND username NOT IN ('FTLDB', 'PLSCOPE', 'UT3')
),
-- materialize relevant PL/Scope identifiers to avoid very bad execution plans
identifiers AS (
SELECT --+ materialize
owner,
object_type,
object_name
FROM dba_identifiers i
WHERE usage_context_id = 0
AND object_type IN ('PACKAGE BODY', 'TYPE BODY', 'FUNCTION', 'PROCEDURE', 'TRIGGER')
),
-- PL/SQL objects without PL/Scope metadata
missing_plscope_obj AS (
SELECT o.owner, o.object_type, o.object_name
FROM dba_objects o
JOIN app_user u ON u.username = o.owner
LEFT JOIN identifiers i
ON i.owner = o.owner
AND i.object_type = o.object_type
AND i.object_name = o.object_name
WHERE o.object_type IN ('PACKAGE BODY', 'TYPE BODY', 'FUNCTION', 'PROCEDURE', 'TRIGGER')
AND i.object_name IS NULL
),
-- PL/SQL bodies extended by has_dml and has_transaction colums using PL/Scope
plscope_obj AS (
SELECT s.owner, s.object_type, s.object_name,
MAX (
CASE
WHEN s.type IN ('INSERT', 'UPDATE', 'DELETE', 'MERGE') THEN
1
ELSE
0
END
) AS has_dml,
MAX (
CASE
WHEN s.type IN ('COMMIT', 'ROLLBACK') THEN
1
ELSE
0
END
) AS has_transaction
FROM dba_statements s
JOIN app_user u ON u.username = s.owner
WHERE s.object_type IN ('PACKAGE BODY', 'TYPE BODY', 'FUNCTION', 'PROCEDURE', 'TRIGGER')
GROUP BY s.owner, s.object_type, s.object_name
),
-- dba_dependencies reduced to a PL/SQL bodies
dep_base AS (
SELECT owner,
type,
name,
referenced_owner,
CASE referenced_type
WHEN 'PACKAGE' THEN 'PACKAGE BODY'
WHEN 'TYPE' THEN 'TYPE BODY'
ELSE referenced_type
END AS referenced_type,
referenced_name
FROM dba_dependencies d
WHERE referenced_type IN ('PACKAGE', 'PACKAGE BODY', 'TYPE', 'TYPE BODY', 'FUNCTION', 'PROCEDURE', 'SYNONYM')
and (owner = 'PUBLIC' OR owner IN (SELECT username FROM app_user))
and (referenced_owner = 'PUBLIC' OR referenced_owner IN (SELECT username FROM app_user))
),
-- extend dependencies by columns has_dml and has_transaction
dep AS (
select d.owner,
d.type,
d.name,
d.referenced_owner,
d.referenced_type,
d.referenced_name,
nvl(p.has_dml, 0) AS referenced_has_dml,
nvl(p.has_transaction, 0) AS referenced_has_transaction
FROM dep_base d
LEFT JOIN plscope_obj p
ON p.owner = d.referenced_owner
AND p.object_type = d.referenced_type
AND p.object_name = d.referenced_name
),
-- XML because JSON values are still restricted to 4000/32767 bytes
-- see Bug 27199654 : ORA-40459 WHEN GENERATING JSON DATA
xml_dep AS (
SELECT XMLELEMENT("xml",
XMLAGG(
XMLELEMENT("row",
XMLELEMENT("key",
XMLELEMENT("owner", d.owner),
XMLELEMENT("type", d.type),
XMLELEMENT("name", d.name)
),
XMLELEMENT("value",
XMLAGG(
XMLELEMENT("dependency",
XMLELEMENT("referenced_owner", d.referenced_owner),
XMLELEMENT("referenced_type", d.referenced_type),
XMLELEMENT("referenced_name", d.referenced_name),
XMLELEMENT("referenced_has_dml", d.referenced_has_dml),
XMLELEMENT("referenced_has_transaction", d.referenced_has_transaction)
)
)
)
)
)
) AS xmldoc
FROM dep d
JOIN dba_objects o
ON d.owner = o.owner
AND d.type = o.object_type
AND d.name = o.object_name
WHERE o.owner IN (SELECT username FROM app_user)
AND o.object_type IN ('PACKAGE BODY', 'TYPE BODY', 'FUNCTION', 'PROCEDURE')
AND (d.owner, replace(d.type, ' BODY'), d.name) IN (
SELECT owner, type, table_name
FROM dba_tab_privs
)
GROUP BY d.owner, d.type, d.name
),
-- get the object dependencies via PL/SQL function
-- passing data as XML because the PL/SQL function dont't have access to named subqueries
dep_hier AS (
SELECT owner, type, name, referenced_owner, referenced_type, referenced_name,
referenced_has_dml, referenced_has_transaction
FROM XMLTABLE(
'/xml/row'
PASSING get_dep((SELECT xmldoc from xml_dep))
COLUMNS owner VARCHAR2(128) PATH 'owner',
type VARCHAR2(128) PATH 'type',
name VARCHAR2(128) PATH 'name',
referenced_owner VARCHAR2(128) PATH 'referenced_owner',
referenced_type VARCHAR2(128) PATH 'referenced_type',
referenced_name VARCHAR2(128) PATH 'referenced_name',
referenced_has_dml INTEGER PATH 'referenced_has_dml',
referenced_has_transaction INTEGER PATH 'referenced_has_transaction'
)
),
-- aggregate columns has_dml and has_transaction per root PL/SQL body
app_plsql AS (
SELECT owner, type AS object_type, name AS object_name,
MAX(referenced_has_dml) AS has_dml,
MAX(referenced_has_transaction) AS has_transaction
FROM dep_hier
GROUP by owner, type, name
),
-- roles as recursive structure
role_base AS (
-- roles without parent (=roots)
SELECT r.role, NULL AS parent_role
FROM dba_roles r
WHERE r.role NOT IN (
SELECT p.granted_role
FROM role_role_privs p
)
UNION ALL
-- roles with parent (=children)
SELECT granted_role AS role, role AS parent_role
FROM role_role_privs
),
-- roles tree, calculate role_path for every hierarchy level
role_tree AS (
SELECT role,
parent_role,
sys_connect_by_path(ROLE, '/') AS role_path
FROM role_base
CONNECT BY PRIOR role = parent_role
),
-- roles graph, child added to all ancestors including self
-- allows simple join to parent_role to find all descendants
role_graph AS (
SELECT DISTINCT
role,
regexp_substr(role_path, '(/)(\w+)', 1, 1, 'i', 2) AS parent_role
FROM role_tree
),
-- user system privileges
sys_priv AS (
-- system privileges granted directly to users
SELECT u.username, p.privilege
FROM dba_sys_privs p
JOIN app_user u ON u.username = p.grantee
UNION
-- system privileges granted directly to PUBLIC
SELECT u.username, p.privilege
FROM dba_sys_privs p
CROSS JOIN app_user u
WHERE p.grantee = 'PUBLIC'
AND p.privilege NOT IN (
SELECT r.role
FROM dba_roles r
)
UNION
-- system privileges granted to users via roles
SELECT u.username, p.privilege
FROM dba_role_privs r
JOIN app_user u ON u.username = r.grantee
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_sys_privs p ON p.grantee = g.role
UNION
-- system privileges granted to PUBLIC via roles
SELECT u.username, p.privilege
FROM dba_role_privs r
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_sys_privs p ON p.grantee = g.role
CROSS JOIN app_user u
WHERE r.grantee = 'PUBLIC'
),
-- user object privileges
obj_priv AS (
-- objects granted directly to users
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_tab_privs p
JOIN app_user u ON u.username = p.grantee
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
UNION
-- objects granted to users via roles
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_role_privs r
JOIN app_user u ON u.username = r.grantee
JOIN role_graph g ON g.parent_role = r.granted_role
JOIN dba_tab_privs p ON p.grantee = g.role
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
-- objects granted to PUBLIC
UNION
SELECT u.username, p.owner, p.type AS object_type, p.table_name AS object_name
FROM dba_tab_privs p
CROSS JOIN app_user u
WHERE p.owner IN (
SELECT u2.username
FROM app_user u2
)
AND p.grantee = 'PUBLIC'
),
-- issues if user is configured in the connection pool of a middle tier
issues AS (
-- privileges not part of CONNECT role
SELECT username,
'SYS' AS owner,
'PRIVILEGE' AS object_type,
privilege AS object_name,
'Privilege is not part of the CONNECT role' AS issue
FROM sys_priv
WHERE privilege NOT IN ('CREATE SESSION', 'SET CONTAINER')
-- access to non PL/SQL units
UNION ALL
SELECT username,
owner,
object_type,
object_name,
'Access to non-PL/SQL unit'
FROM obj_priv
WHERE object_type NOT IN ('PACKAGE', 'TYPE', 'FUNCTION', 'PROCEDURE')
-- own objects
UNION ALL
SELECT u.username,
o.owner,
o.object_type,
o.object_name,
'Connect user must not own any object'
FROM app_user u
JOIN dba_objects o ON o.owner = u.username
-- missing CREATE SESSION privilege
UNION ALL
SELECT u.username,
'SYS',
'PRIVILEGE',
'CREATE SESSION',
'Privilege is missing, but required'
FROM app_user u
WHERE u.username NOT IN (
SELECT username
FROM sys_priv
WHERE privilege = 'CREATE SESSION'
)
-- missing PL/Scope metadata leads to wrong results
UNION ALL
SELECT p.username,
p.owner,
p.object_type,
p.object_name,
'PL/Scope metadata is missing, required for analysis'
FROM obj_priv p
JOIN missing_plscope_obj s
ON s.owner = p.owner
AND replace(s.object_type, ' BODY') = p.object_type
AND s.object_name = p.object_name
-- access to PL/SQL units updating database state without COMMIT/ROLLBACK
UNION ALL
SELECT p.username,
p.owner,
p.object_type,
p.object_name,
'INSERT/UPDATE/DELETE/MERGE without COMMIT/ROLLBACK'
FROM obj_priv p
JOIN app_plsql a
ON a.owner = p.owner
AND replace(a.object_type, ' BODY') = p.object_type
AND a.object_name = p.object_name
WHERE p.object_type IN ('PACKAGE', 'TYPE', 'FUNCTION', 'PROCEDURE')
AND a.has_dml = 1 AND a.has_transaction = 0
),
-- aggregate issues per user
issue_aggr AS (
SELECT u.username, COUNT(i.username) issue_count
FROM app_user u
LEFT JOIN issues i ON i.username = u.username
GROUP BY u.username
),
-- user summary (calculate is_smartdb_property_3_met)
summary AS (
SELECT username,
CASE
WHEN issue_count = 0 THEN
'YES'
ELSE
'NO'
END AS is_smartdb_property_3_met,
issue_count
FROM issue_aggr
ORDER BY is_smartdb_property_3_met DESC, username
)
-- main
SELECT *
FROM summary
WHERE issue_count = 0;
/USERNAME IS_SMARTDB_PROPERTY_3_MET ISSUE_COUNT
------------------------ ------------------------- -----------
APEX_REST_PUBLIC_USER YES 0
THE_BAD_USER YES 0
THE_GOOD_USER YES 0If you are using a connect user that is not listed as a result, then your application is not SmartDB.
The query checks also the SmartDB properties 1 and 2. However, the query produces only a result if the PL/SQL bodies in application users are compiled with PL/Scope (see script above). Change the main part of the query to SELECT * from issues if you want to know why a connect user is not shown in the result.
BTW: the check results for the SmartDB properties 2 and 3 are identical because THE_BAD_USER and THE_GOOD_USER do not have access to write operations.
4. SQL statements are written by human hand
If you generate SELECT, INSERT, UPDATE, DELETE or MERGE statements, then your application is not SmartDB.
I see the following reasons to generate code (including SQL statements):
- Don’t repeat yourself (DRY principle). Striving for DRYness leads to better data models, better designs and better code. In some cases, code generators are required to achieve the goal.
- Reduce the overall complexity by using a domain-specific language (DSL). Enforce rules and conventions in the DSL and the code templates. This leads to a smaller code base and improves productivity.
A generator creates code at design/build time or at runtime. Both approaches have pros and cons. Code generators producing code at runtime are easier to deploy but may produce more runtime errors, are harder to debug and come with a performance penalty. Code generators producing code at design/build time are more extensive and more costly to deploy, are much easier to debug, have better runtime performance and produce errors at install time rather than runtime.
Even if generated code should look like written by human hand, it should never become a part of your code base. Generated code is derived from something else. This “something else” (generator, code templates, generator input) is part of your code base. Do not amend generated code and keep your code base as small as possible. It’s okay to keep the generated code also in the version control system, but you should separate it from the “real code base”. It should be absolutely clear that the generated code is completely replaced by a subsequent generator run.
Code generators offer a high value when used correctly. Therefore, the general ban on the use of generators is simply ignorant.
5. SQL statements exploit the full power of set-based SQL
If you use row-by-row processing when set-based SQL is feasible and noticeably faster, then your application is not SmartDB.
This is the most important SmartDB property. Set-based SQL is the key to good performance. It means that you are using the database as a processing engine and not as a data store only.
You should make it a habit to minimize the total number of executed SQL statements to get a job done. Less loops, more set-based SQL. In the end, it is simpler. You tell the database what you want and the optimizer figures out how to do it efficiently.
Conclusion
If you use set-based SQL in your application and manually craft your SQL statements, then you can check with a single SQL statement, if your application is really SmartDB. Don’t be disappointed, if it is not. Besides some demo applications, I haven’t seen a SmartDB application and I do not expect to see one soon.
The SmartDB idea is based on sound analysis and some good advice (see Toon Koppelaar’s excellent video and slide deck). But the resulting SmartDB definition overshoots the mark. It focuses too much on PL/SQL and ignores the capabilities of database-aware tools. These tools support SQL (or MDX) as the primary interface to the database (especially for queries). Using another path to the database is usually possible, but less efficient from a development cost and time-to-market perspective.
It looks like there is currently no way to refine the SmartDB definition making this approach broadly usable. The recommended alternative is to come up with your own definition. My next post is dealing with that topic. However, I’d still like to see a SmartDB 2.0 definition that tolerates views as part of the API, generated code and transaction control statements by the API caller.
6 Comments
[…] Would you like to know if your database application is SmartDB compliant? Then see my previous blog post. There’s a script you can run to find […]
[…] If you breaking your monolithic applications into smaller parts to allow teams to control “their own destiny”, then you must be aware that these smaller parts are in fact not independent. Treating the database as a persistence layer only will lead to applications that are mimicking database functionality in a less efficient way. For small applications you won’t notice the difference, but you will on a larger scale. The solution is simple. Use the database as processing engine as recommended by PinkDB and SmartDB. […]
[…] took the liberty of adding headers for the SmartDB properties I’ve described in this post. At that time I assumed that all these five properties were mandatory, which in fact only holds […]
Hi Philipp,
what is the reason for not allowing Views as a data access mechanism but force PL/SQL in here? I understand that you don’t want to expose tables to the outer world, but views to me seem to be as flexible and “secure” as a PL/SQL API will be and might interact more smoothly with a UI technology such as APEX.
What do you think?
Hi Jürgen,
The term SmartDB was defined by Bryn Llewellyn. Here’s the relevant slide (a screenshot of his SmartDB talk at Kscope18):
The point of this blog post was to show that it is quite difficult to produce something like a SmartDB compliant application. As mentioned in the conclusion, beside some demo apps I have never seen that in real live.
IMO the SmartDB paradigm is too extreme. After various discussions with Bryn and others I decided to define a more practical paradigm. PinkDB. SmartDB is a subset of PinkDB. I’m not against stored objects. Quite the contrary. However, I still like to use views as part of a database API. You find my thoughts also in this interview, it was published in the Red Stack Magazine 03/2020 on page 70-71.
In the “Differences to SmartDB” section of the PinkDB blog post I said the following:
This should make my position regarding “views” clear.
Thanks,
Philipp
Hi Philipp,
I totally agree with you on that. One could maybe look at the view as a separate way to provide inter database access to the data as an alternative to a JSON/REST based approach or similar for other application. As APEX resides in the database, it would be crazy to force it to use REST to access data that is just “one schema away”, as it would be crazy to convert data to some kind of object deliverable by a table function just to pass it between schemas.